

사물 인터넷 기술

산업 제조
1990년 Arnold Schwarzenegger 영화 Total Recall 거의 한 세기 뒤인 2084년의 이야기를 그리고 있습니다. 영화에 따르면 미래에는 자율주행 자동차가 등장할 것입니다. 이것은 1990년에는 공상과학 소설이었지만 오늘날에는 현실입니다. Apple, Alphabet, Nissan, Uber 및 더 많은 회사가 자율주행차를 개발하고 있습니다. Tesla는 기능이 뛰어난 자율주행차를 최종 소비자에게 판매하고 있는데 잘 작동하는 것 같습니다.
불과 30년 만에 SF를 현실로 만든 것은 무엇일까요? 정답은 딥 러닝입니다.
불과 금속 세공의 그리스 신 헤파이스토스는 황금 로봇과 기계를 만들었습니다. 1770년대에 기계식 Turk 시대부터 인간은 인간의 지능을 모방한 장치를 개발해 왔습니다. 기계식 터키인은 속임수였지만, 20세기 후반에는 인간을 무찌를 수 있는 컴퓨터가 나중에 개발되었습니다. 이 모든 것은 인간의 두뇌를 모방할 수 있는 시스템을 만들기 위한 노력이었습니다.

인공 지능(AI)은 인간의 두뇌를 모방하려는 모든 컴퓨팅 시스템에 주어진 용어입니다. Alan Turing의 Turing 기계는 논리를 사용하여 솔루션에 도달하는 원시 AI 시스템이었습니다.
머신 러닝(ML)은 모델을 사용하여 작업을 수행하는 AI의 하위 집합입니다. 이러한 모델은 많은 양의 데이터로 학습됩니다. 1997년 세계 체스 챔피언 Garry Kasparov를 이긴 컴퓨터 Deep Blue가 머신러닝의 한 예입니다.
딥 러닝은 다시 모델이 사람의 감독 없이 데이터에서 학습하는 ML의 하위 집합입니다. 따라서 딥 러닝 시스템은 비정형 데이터에 대한 비지도 학습이 가능합니다.
딥 러닝은 정보를 전달하고 처리하는 뉴런을 구성하는 인간 두뇌의 구조에서 영감을 받았습니다. 딥 러닝에 사용되는 구조를 인공 신경망(ANN)이라고 합니다. ANN은 사람의 감독 없이 정보를 식별하고 분류할 수 있으며 감독되지 않은 학습이 가능하다고 합니다. 이를 위해서는 지도 학습을 사용하는 기존 ML에 비해 훨씬 더 많은 양의 데이터가 필요합니다.
ANN은 데이터가 통과하는 입력 레이어에서 출력 레이어까지 여러 레이어로 구성됩니다. 입력 레이어와 출력 레이어를 제외한 나머지 레이어를 은닉 레이어라고 합니다. ANN의 첫 번째 레이어 또는 입력 레이어는 뉴런으로 구성됩니다. ANN의 뉴런은 인간의 뉴런을 밀접하게 나타내는 수학적 기능입니다.
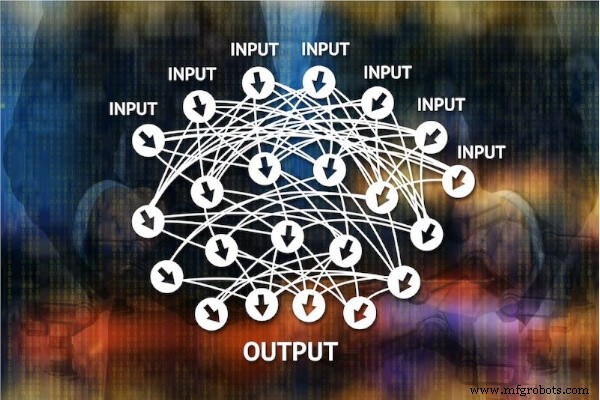
서로 다른 계층을 통한 정보 전송은 연결 채널을 통해 이루어집니다. ANN 계층의 모든 노드는 이러한 채널을 통해 다음 계층의 모든 노드에 연결됩니다. 각 채널에는 가중치라고 하는 값이 첨부되어 있습니다. 따라서 채널을 가중 채널이라고 합니다.
은닉층의 모든 뉴런에는 편향이라고 하는 고유 번호가 있습니다. 정보는 채널과 관련된 가중치를 사용하여 한 계층에서 다음 채널로 전달됩니다. 다음 계층의 뉴런에 도달하면 바이어스가 입력의 가중치 합에 추가됩니다.
이 수학적 연산의 결과는 활성화 함수에 제공됩니다. 활성화 함수는 뉴런이 활성화되어야 하는지 여부를 결정합니다. 이것은 채널의 가중치 합에 편향을 추가하여 얻은 결과에 비선형 활성화 함수를 적용하여 수행됩니다. 활성화 함수는 뉴런의 출력에 비선형성을 추가합니다.
활성화 함수를 적용한 후에 활성화된 뉴런만이 다음 계층으로 정보를 보낼 수 있습니다. 이것은 최종 레이어인 출력 레이어까지 계속됩니다. 뉴런 채널의 가중치와 은닉층의 편향은 잘 훈련된 모델을 수신하도록 지속적으로 조정됩니다.
가장 인기 있는 딥 러닝 프레임워크는 다음과 같습니다.
<울>
데이터는 딥 러닝의 원료입니다. 이론적으로 데이터의 양에 관계없이 모델이 향상됩니다. 그러나 데이터 수집 노력, 필요한 훈련 시간, 모델 훈련에 필요한 연산 능력을 고려할 때 딥 러닝을 위한 데이터의 양은 무한할 수 없습니다. 반대로 데이터가 너무 적으면 신뢰할 수 있는 딥 러닝 모델이 생성되지 않습니다.
성공적인 모델을 훈련하는 데 필요한 데이터 양에 대한 정해진 규칙은 없습니다. 주로 훈련된 모델의 결과에 따라 다릅니다. 모델이 적절하게 신뢰할 수 없으면 더 많은 데이터가 필요합니다. 딥 러닝 모델을 훈련하는 데 필요한 최소 데이터에 대한 몇 가지 경험 법칙이 있습니다.
<울>다음은 딥 러닝을 사용하는 보다 일반적인 응용 프로그램에 대한 두 가지 휴리스틱입니다. 데이터 엔지니어는 다양한 애플리케이션에 대해 유사한 규칙을 옹호합니다. 모든 경험 법칙과 마찬가지로 이는 완벽하지 않으며 특정 응용 프로그램에 따라 변경해야 합니다.
딥 러닝을 위한 많은 산업 응용 프로그램이 있습니다. 그 중 몇 가지를 살펴보겠습니다.
자율주행차는 현재 소비자들에게 판매되고 있지만 산업적으로도 많이 활용되고 있습니다. 자율 주행은 공장에서 사용되는 운송 장치에 통합될 수 있습니다. 예를 들어, AGV(Autonomous Guided Vehicles)는 완전히 자율적으로 이동할 수 있습니다. 이를 통해 이러한 작업에서 수작업이 필요하지 않으며 동시에 안전과 효율성이 향상됩니다.

컴퓨터는 이미지에서 물체를 분류하고 인식합니다. 때때로 컴퓨터 비전은 자율주행 차량의 일부이지만 산업용 애플리케이션에서 더 많이 사용됩니다. 컴퓨터 비전은 개체 정렬을 자동화할 수 있습니다. 컴퓨터 비전 지원 시스템은 품질 검사를 수행할 수 있습니다. 또한 공장 구내 및 산업 공정의 감시를 자동화할 수 있습니다.
회사의 공급망은 여러 공급업체, 공급업체, 지역 및 규정에 걸쳐 있는 복잡한 시스템입니다. 엄청난 양의 상품을 수동으로 관리하는 것은 불가능한 작업입니다. 딥 러닝은 공급망에서 IoT(사물 인터넷) 장치의 도움으로 생성된 대용량 데이터를 분석하여 건강한 공급망을 유지하는 데 사용할 수 있습니다.
딥 러닝은 또한 많은 의료 응용 프로그램을 가지고 있습니다. X-ray, MRI 등과 같은 의료 영상 결과에서 이상을 식별하는 데 사용할 수 있습니다. 또한 24시간 내내 부착된 모니터링 장치로 환자의 건강을 모니터링할 수 있습니다. 딥 러닝은 가장 가능성 있는 분자 조합을 제공하여 약물 발견을 지원할 수 있습니다.
딥 러닝은 항공 우주, 우주 탐사, 광업, 항법, 방위 시스템, 사이버 보안 분야에서 더 많은 산업 응용 프로그램을 가지고 있으며 목록은 계속됩니다. 딥 러닝은 모든 산업 분야에서 빠르게 채택되고 있으며 곧 Industry 4.0의 필수 요소이자 피할 수 없는 요소가 될 것입니다.
사물 인터넷 기술
만들고 싶은 이미지가 있으신가요? 3D 프린팅은 상상의 대상을 쉽게 만들 수 있는 플랫폼을 제공합니다. 의학, 교육, 건축 또는 기타 기술 기반 분야에서 일하든 3D 프린팅은 종종 유용합니다. 그렇다면 3D 프린팅이란 무엇일까요? 이 기사를 읽고 3D 프린팅 질문에 대한 올바른 답을 얻으십시오. 3D 프린팅은 간단히 말해서 3D 프린팅 장치를 사용하여 3D 모델을 만드는 과정입니다. 선택한 3D 프린팅 장치에서 플라스틱 필라멘트를 압출하면 3차원 물체를 한 층씩 만들게 됩니다. 고품질 3D 프린터를 사용하면 중요한 세부 사
N은 펌프의 중요한 문자입니다. 용기에 담긴 액체의 부피를 계산하는 데 도움이 되는 숫자이며 여러 단위로 사용할 수 있습니다. 이 기사에서는 N을 사용하여 펌프, 저장소 및 유체 흐름과 관련된 문제를 해결하는 방법을 알려드립니다. 펌프에 대한 사람들의 가장 일반적인 질문 중 하나는 Pump N의 N이 무엇을 의미하는지입니다. 정답은 질소입니다. 질소는 펌프 성능의 필수 요소이며 모든 것이 원활하게 작동하도록 도와줍니다. 질소는 밸브, 씰 및 베어링과 같은 다른 부품의 제조에도 사용됩니다. 펌프의 N은 어떻게 작동하나요? N in