

산업기술

산업 제조
지금까지 모든 사람들은 머신 러닝과 머신 러닝이 모든 것을 어떻게 변화시킬지에 대해 들었습니다. 하지만 모든 것을 어떻게 바꿔야 할지 아는 사람은 거의 없습니다. 이 블로그의 단계를 시도하거나 이에 대해 읽을 때 PLCnext 컨트롤러로 변경을 시작하는 방법을 이해하는 데 도움이 되기를 바랍니다. 이 블로그에서는 첫 번째 ML 모델을 교육하고 ONNX 표준으로 변환하고 PLCnext 컨트롤러에서 모델을 추론하는 방법에 대해 설명합니다. 진행하지 않고 압도적인 일을 만들기 위해 저는 유명한 Iris 데이터 세트를 사용하여 모델을 구축할 것입니다.
시작하기 전에 우리가 달성하려는 것이 무엇인지 매우 명확해야 합니다. 따라서 이 블로그에서 다루는 주제에 대해 간단히 설명하겠습니다. 내 참조는 이 블로그의 끝에서 찾을 수 있습니다.
따라서 기계 학습이 무엇인지 설명하는 것으로 시작해야 할 것 같습니다. 머신 러닝의 핵심은 통계와 알고리즘을 사용하여 데이터 세트에서 패턴을 찾으려고 한다는 것입니다. 우리는 지도 머신 러닝, 비지도 머신 러닝 및 강화 학습의 세 가지 주요 유형의 머신 러닝을 구분합니다. 지도 학습은 오늘날 가장 많이 사용되는 "맛"이며 이 블로그에서는 지도 학습을 사용할 것입니다. 지도 학습에서는 데이터에 레이블을 지정하고 우리가 찾고 있는 패턴이 정확히 무엇인지 기계에 알려줍니다.
비지도 학습에서는 데이터에 레이블을 지정하지 않고 기계가 고유한 패턴을 찾도록 합니다. 이 기술은 응용 프로그램이 덜 명확하기 때문에 비지도 학습이 덜 유명하기 때문입니다.
마지막으로, 강화 학습에서 알고리즘은 명시된 목표를 달성하기 위해 시행착오를 통해 학습합니다. 그냥 이것저것 많이 시도하고 좋은 행동인지 나쁜 행동인지에 따라 보상을 받거나 벌점을 받습니다. Google의 AlphaGo는 강화 학습의 유명한 예입니다.
Wikipedia에 따르면 Iris 꽃 데이터 세트는 다음과 같습니다.
알겠습니다. 하지만 어떻게 보이나요?
Iris 데이터셋에는 꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비 및 붓꽃의 다양성의 5개 필드가 있습니다. 오늘의 목표는 꽃받침 길이, 꽃받침 너비, 꽃잎 길이 및 꽃잎 너비를 알 때 붓꽃의 종류를 찾는 것입니다. 그래서 우리는 꽃의 종류를 분류하기 위해 모델을 훈련할 것입니다. 짐작할 수 있듯이 이러한 유형의 기계 학습은 분류입니다.
머신 러닝을 사용하여 데이터 세트의 값을 예측할 수도 있습니다. 이것은 회귀라는 이름의 절차이며 분류와 다른 알고리즘을 사용합니다.
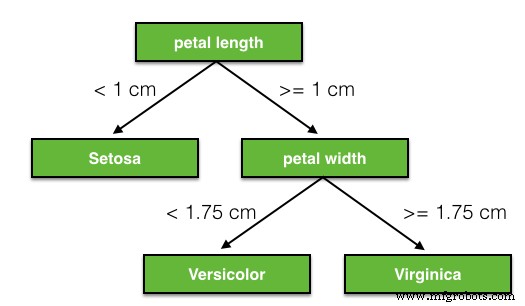
오늘 우리는 "Decision Tree Classifier"를 사용할 것입니다. 그것이 작업에 완벽하기 때문이 아니라 매우 직관적이고 멋진 수학 없이도 쉽게 이해할 수 있기 때문입니다. 여기에서 붓꽃 데이터 세트에 대한 의사결정 트리의 예를 찾을 수 있습니다.
상상할 수 있듯이 기계 학습 모델은 다양한 형식으로 제공될 수 있으며 다양한 가속 방법을 사용하여 다양한 하드웨어에서 실행해야 합니다. Open Neural Network Exchange는 이 문제를 완화하려고 합니다. 오픈 오피스, azure 및 전 세계의 수많은 기타 애플리케이션에서 사용됩니다. 이 블로그를 읽고 있는 기기에서 거의 확실히 사용됩니다.
onnx 모델을 실행하려면 onnx 런타임이 필요하며 이는 도전과제를 수반합니다. 특히 암 프로세서에서는 도커 이미지가 제공되므로 문제가 없을 것입니다!
펌웨어 2021.0 LTS가 설치된 AXC F 2152 컨트롤러와 모델을 학습시키기 위해 Ubuntu 20.04 VM을 사용하고 있습니다. 모델 학습 및 추론을 위한 스크립트가 제공되지만 Ubuntu VM 설정은 블로그 범위를 벗어납니다. 필요한 Python 패키지를 설치하는 방법에 대한 좋은 설명을 찾을 수 있으며 사용된 모든 패키지는 pip3으로 올바르게 설치되어야 합니다.
PLCnext 컨트롤러에는 컨테이너 엔진이 설치되어 있어야 합니다. 여기에서 절차에 대한 좋은 설명을 찾을 수 있습니다.
AXC F 3152에서도 유사한 절차가 가능합니다.
이 블로그에서는 Python 및 컨테이너에 대한 최소한의 경험이 필요합니다.
이 GitHub 저장소의 콘텐츠를 다운로드하고 필요한 모든 패키지가 설치되어 있는지 확인하십시오.
우리가 실행할 첫 번째 스크립트는 우리 모델을 홍채 데이터 세트에 맞추려는 기차 스크립트입니다.
아래에서 이 교육 스크립트에서 발췌한 코드를 찾을 수 있습니다. 이 스크립트는 마녀가 훈련된 모델을 포함하는 ".onnx" 파일을 생성합니다.
# Slit the dataset in a training and testing dataset
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, Y_test = train_test_split(X, y)
# Define the model and fit the model with training data and print information about the model
clr = DecisionTreeClassifier()
clr.fit(X_train, y_train)
print(clr)
#Convert the model from sklearn format to ONNX (Open Neural Network Exchange)
initial_type = [('float_input', FloatTensorType([None, 4]))]
onx = convert_sklearn(clr, initial_types=initial_type)
with open("decision_tree_iris.onnx", "wb") as f:
f.write(onx.SerializeToString())
개발 중인 머신에서 모델을 실행하여 모델을 확인하십시오. 추론 스크립트를 실행할 때 붓꽃의 종류에 해당하는 2개의 정수를 얻어야 합니다.
import numpy as np
import onnxruntime as rt
X_test = np.array([[5.8,4.0,1.2,0.2],[7.7,3.8,6.7,2.2,]])
sess = rt.InferenceSession("decision_tree_iris.onnx")
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onx = sess.run(
[label_name], {input_name: X_test.astype(np.float32)})[0]
print(pred_onx)
output : [0 2]
즐겨 사용하는 sFTP 클라이언트를 열고 ".onnx" 및 "inference.py" 저장소를 PLCnext 컨트롤러의 /opt/plcnext/onnx에 놓습니다. 다음 명령을 루트로 계속 실행하십시오.
balena-engine run -it --name onnx -v /opt/plcnext/onnx/:/app pxcbe/onnx-runtime-arm32v7
를 사용하여 파이썬 추론 스크립트를 실행하십시오.
cd /app
python3 /app/inference.py
모든 것이 잘 되었다면 Ubuntu VM의 추론과 동일한 출력을 얻을 수 있습니다! 축하합니다. 끝까지 해내셨습니다. 이제 물건을 바꾸십시오!
사실 아직 끝나지 않았습니다. 붓꽃 분류는 재미있지만 논리적 컨트롤러에서 여러 응용 프로그램을 상상할 수는 없습니다. 모델을 추론할 수 있도록 고유한 모델을 만들고 해당 모델에 대한 API를 만들어야 합니다. OPC UA를 사용하여 모델에 데이터를 전달하거나 해당 모델에 대한 사용자 지정 REST 엔드포인트를 구축하도록 선택할 수 있습니다. 어쨌든 내가 제공한 것보다 더 많은 코드를 작성해야 합니다.
문자 그대로 이미지를 구축하는 데 며칠과 잠 못 이루는 밤이 걸렸다는 점을 고려하면 제공된 이미지 위에 이미지를 구축하는 것이 좋습니다. 참조에서 Python 컨테이너 앱을 빌드하는 데 유용한 리소스를 찾을 수 있습니다.
이 비디오를 보려면 마케팅 쿠키를 수락하십시오.
https://www.researchgate.net/Figure/Decision-tree-for-Iris-dataset_fig1_293194222https://onnx.ai/
https://github.com/PLCnext/Docker_GettingStarted
https://www.wintellect.com/containerize-python-app-5-minutes/
산업기술
작성:Adam Poole, 제품 디자인 책임자 기술은 우리의 삶을 더 쉽게 만들어 줄 때만 가치가 있지만 최신 기술 마술을 홍보하는 과정에서 그 단순한 진실을 잃을 수 있습니다. 작업 환경에서 사람들에게 마지막으로 필요한 것은 관리해야 할 추가 시스템에 대한 골칫거리를 남기는 솔루션입니다. 스마트 공장과 인더스트리 4.0을 둘러싼 혁신과 열정의 물결 속에서 사람들의 직장 생활을 더 복잡하게 만드는 것보다 더 강력한 비즈니스를 구축할 수 있도록 지원하는 솔루션을 찾는 것이 그 어느 때보다 중요합니다. 자유롭게 흐르는 데이터는
머신 러닝은 인공 지능의 일부이며 기계가 직접 프로그래밍하지 않고 실제 데이터에서 학습하는 것으로 구성됩니다. 이 게시물에서는 이러한 알고리즘이 업계에 가져올 수 있는 이점을 사용하는 방법을 살펴보겠습니다. 머신러닝 머신 러닝은 인공 지능의 한 분야입니다. (AI) 기계가 알고리즘을 통해 학습할 수 있도록 합니다. 이러한 알고리즘은 모델이 생성되는 실제 데이터에서 학습합니다. 이 모델을 사용하면 새 데이터가 어떤 클래스 또는 유형인지 예측할 수 있습니다. 기계 학습 내에는 지도 학습과 비지도 학습의 두 가지 유형이 있습니다