

임베디드

산업 제조
이 기사는 Perceptron 신경망에 대한 시리즈의 일부입니다.
처음부터 시작하거나 앞으로 나아가고 싶다면 여기에서 다른 기사를 확인할 수 있습니다.
<올>
이전 기사에서 우리는 신경망이 레이어로 배열된 상호 연결된 노드로 구성되는 것을 보았습니다. 입력 계층의 노드는 데이터를 분배하고 다른 계층의 노드는 합산을 수행한 후 활성화 함수를 적용합니다. 이러한 노드 간의 연결에는 가중치가 적용됩니다. 즉, 각 연결은 전송된 데이터에 스칼라 값을 곱합니다.
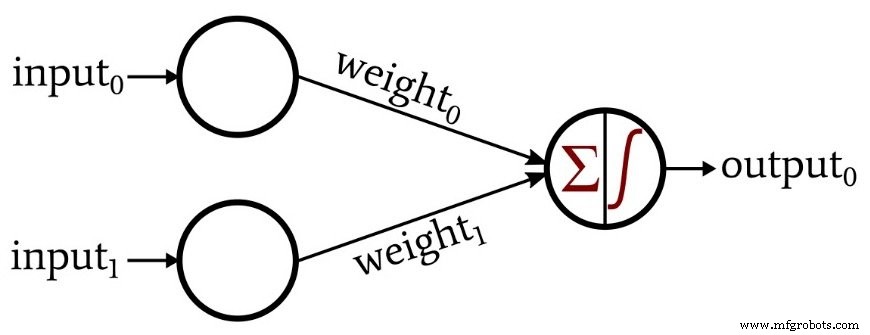
이 구성을 단일 레이어 퍼셉트론이라고 합니다. 예, 알고 있습니다. 두 개의 레이어(입력 및 출력)가 있지만 계산 노드가 포함된 레이어는 하나만 있습니다.
이 기사에서는 다음 신경망을 사용하여 Perceptron 기능을 살펴보겠습니다.
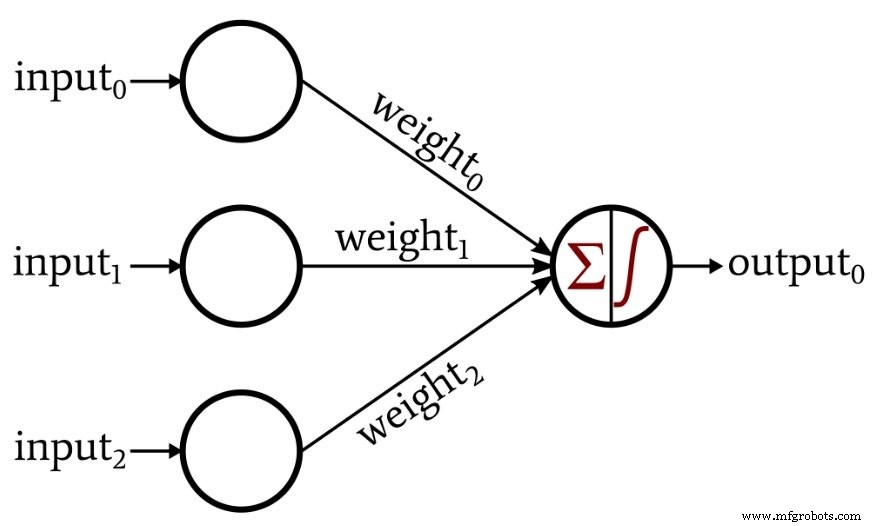
보시다시피 입력 차원은 3입니다. 우리는 이 퍼셉트론을 3차원 공간에서 문제를 해결하기 위한 도구로 생각할 수 있습니다. 예를 들어 다음과 같은 문제를 제안해 보자. 3차원 공간의 한 점이 x축 아래에 있으면 유효하지 않은 데이텀에 해당한다. 점이 x축 위 또는 위에 있으면 추가 분석을 위해 유지해야 하는 유효한 데이텀에 해당합니다. 데이터를 분류하려면 이 중립 네트워크가 필요하며, 출력 값 1은 유효한 데이터를 나타내고 값 0은 잘못된 데이터를 나타냅니다.
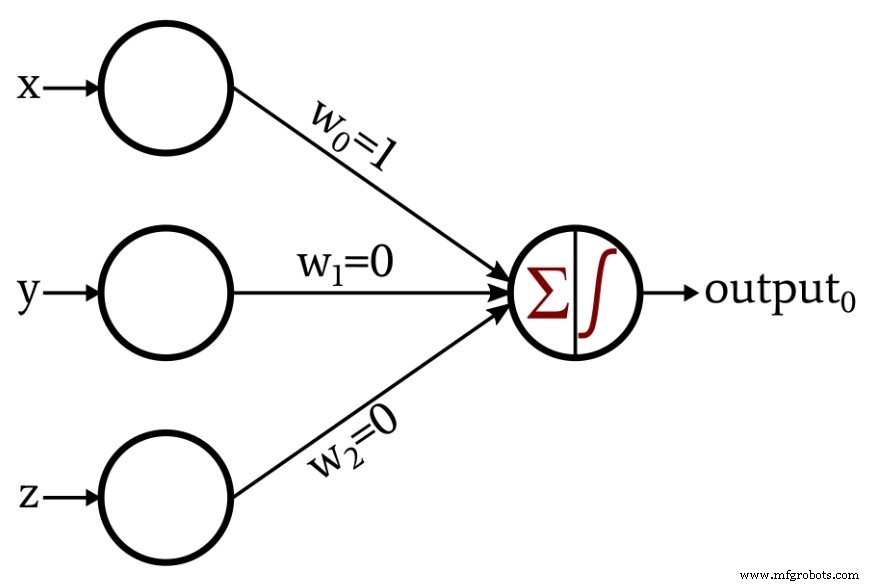
먼저 3차원 좌표를 입력 벡터에 매핑해야 합니다. 이 예에서는 0을 입력합니다. x 구성 요소, input1 는 y 구성 요소이고 2를 입력합니다. 는 z 성분입니다. 다음으로 가중치를 결정해야 합니다. 이 예제는 네트워크를 훈련할 필요가 없을 정도로 간단합니다. 필요한 가중치를 간단히 생각하고 할당할 수 있습니다.
이제 출력 노드의 활성화 함수를 다음과 같이 표현되는 단위 단계로 지정하기만 하면 됩니다.
\[f(x)=\begin{케이스}0 &x <0\\1 &x \geq 0\end{케이스}\]
퍼셉트론은 다음과 같이 작동합니다. 이후 w1 =0 및 w2 =0인 경우 y 및 z 구성요소는 출력 노드에서 생성된 합계에 기여하지 않습니다. 합계에 영향을 미치는 유일한 입력 데이터는 x 구성 요소이며 w0 때문에 수정되지 않은 상태로 출력 노드에 전달됩니다. =1. 3차원 공간의 점이 x축 아래에 있으면 출력 노드의 합은 음수가 되고 활성화 함수는 이 음수 값을 output0으로 변환합니다. =0. 3차원 공간의 점이 x축 위 또는 위에 있으면 합은 0보다 크거나 같으며 활성화 함수는 이것을 output0으로 변환합니다. =1.
이전 섹션에서 저는 Perceptron을 문제 해결 도구로 설명했습니다. 하지만 Perceptron이 많은 문제를 해결하지 못했다는 사실을 눈치채셨을 수도 있습니다. 저는 문제를 해결하고 필요한 가중치를 할당하여 퍼셉트론에 솔루션을 제공했습니다.
이 시점에서 우리는 중요한 신경망 개념에 도달했습니다. 입력 데이터와 원하는 출력 값 간의 관계가 매우 간단하기 때문에 유효/무효 분류 문제를 빠르게 해결할 수 있었습니다. 그러나 많은 실제 상황에서 인간이 입력 데이터와 출력 값 사이의 수학적 관계를 공식화하는 것은 극히 어려울 것입니다. 입력 데이터를 수집하고 해당 출력 값을 기록하거나 생성할 수 있지만 입력에서 출력으로 가는 수학적 경로가 없습니다.
유용한 예는 필기 인식입니다. 손으로 쓴 문자의 이미지가 있고 그 이미지를 "a", "b", "c" 등으로 분류하여 손글씨를 일반 컴퓨터 텍스트로 변환할 수 있다고 가정해 보겠습니다. 쓰고 읽는 방법을 아는 사람은 입력 이미지를 생성한 다음 각 이미지에 올바른 범주를 할당할 수 있습니다. 따라서 입력 데이터와 해당 출력 데이터를 수집하는 것은 어렵지 않습니다. 반면에 입력-출력 쌍을 보고 입력 이미지를 출력 범주로 올바르게 변환하는 수학적 표현이나 알고리즘을 공식화하는 것은 매우 어려울 것입니다.
따라서 필기 인식 및 기타 많은 신호 처리 작업은 정교한 도구의 도움 없이는 인간이 해결할 수 없는 수학적 문제를 제시합니다. 신경망은 생각하고 분석하고 혁신할 수 없다는 사실에도 불구하고 인간이 할 수 없는 일, 즉 잠재적으로 엄청난 양의 수치 데이터와 관련된 계산을 빠르고 반복적으로 수행할 수 있기 때문에 이러한 어려운 문제를 해결할 수 있습니다. .
네트워크 교육
신경망이 입력에서 출력까지 수학적 경로를 생성하도록 하는 프로세스를 훈련이라고 합니다. 입력 값과 해당 출력 값으로 구성된 네트워크 훈련 데이터를 제공하고 이러한 값에 고정된 수학적 절차를 적용합니다. 이 절차의 목표는 네트워크가 이전에 본 적이 없는 입력 데이터로도 올바른 출력 값을 계산할 수 있도록 네트워크의 가중치를 점진적으로 수정하는 것입니다. 본질적으로 훈련 데이터에서 패턴을 찾고 이러한 패턴을 새 데이터에 적용하여 유용한 출력을 생성할 가중치를 생성하는 것입니다.
다음 다이어그램은 위에서 논의한 유효/무효 분류기를 보여주지만 가중치는 다릅니다. 이것은 1000개의 데이터 포인트로 퍼셉트론을 훈련하여 생성한 가중치입니다. 보시다시피 교육 과정을 통해 Perceptron은 내가 인간 스타일의 비판적 사고를 통해 식별한 수학적 관계를 자동으로 근사화할 수 있었습니다.
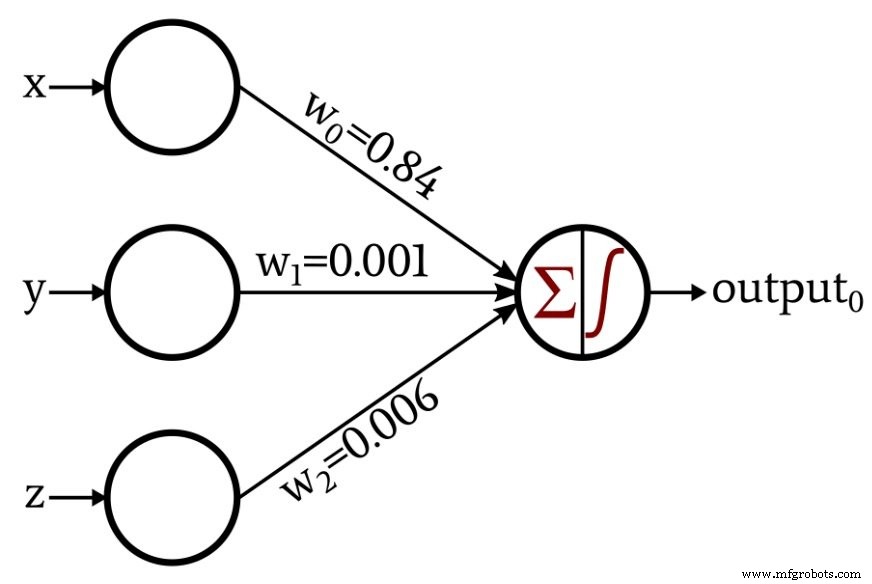
이 퍼셉트론을 훈련한 결과를 보여줬지만 어떻게 이런 결과를 얻었는지에 대해서는 아무 말도 하지 않았습니다. 다음 기사에서는 단일 레이어 Perceptron 신경망을 구현하는 짧은 Python 프로그램에 대해 설명하고 교육 절차도 설명하겠습니다.
임베디드
구성품 및 소모품 서보(타워 프로 MG996R) × 1 Arduino UNO × 1 점퍼 와이어(일반) × 1 UTSOURCE 전자 부품 × 1 이 프로젝트 정보 소개 나는 최근에 서보 모터를 다루는 인간형 로봇을 만들려고 노력했습니다. 로봇을 TALK로 만들기 직전에 모든 것이 잘 작동했습니다. TMRpcm 라이브러리를 사용해야 할 때. 하지만 다음과 같은 라이브러리가 있습니다. #TMRpcm.h#VirtualWire.h A
쉽고 빠르게 충전할 수 있는 프로젝트용 배터리를 찾고 계십니까? 그런 다음 Ni-Cd 배터리를 구입하는 것이 좋습니다. 또한 Ni-Cd 배터리 팩은 내성이 강하고 가혹한 조건에서도 작동합니다. 또한, 배터리는 리튬 배터리 또는 납산 배터리보다 내구성이 뛰어납니다. 알카라인 배터리와 같이 에너지가 높은 기기입니다. 하지만 배터리 충전기가 없다면 어떻게 될까요? 음, 일반적으로 초보자에게 친숙하고 저렴하며 완벽하게 작동하는 간단한 NiCd 배터리 충전기 회로를 사용할 수 있습니다. 따라서 이 기사에서는 NiCd 충전기 등을 사