

제조공정

산업 제조
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 |
 |
|
이 프로젝트는 에 있는 이전 디스크 리더 프로젝트의 작업을 계속합니다. https://create.arduino.cc/projecthub/projects/485582/
자세한 내용은 을 참조하십시오. http://amiga.robsmithdev.co.uk
<울>
데이터 쓰기 - 시도 1
따라서 디스크를 성공적으로 읽을 수 있게 된 후 원래 물리적 매체를 유지하려면 디스크를 다시 쓰기를 원할 수 있다고 생각했습니다. 소프트웨어부터 시작하여 이 작업을 역으로 해결할 것이라고 생각했습니다(예:인터페이스가 어떻게든 쓸 수 있도록 ADF 디스크 파일을 MFM 데이터로 변환 ).
그래서 ADF 디스크를 읽고 모든 섹터를 하나의 트랙으로 인코딩하는 클래스를 추가하는 것으로 시작했습니다. 내가 만든 데이터를 디코딩 부분에 다시 공급하여 잠재적으로 테스트할 수 있다는 것을 알고 이 작업을 시작했습니다. 이 작업을 하는 동안 내 Amiga에 무엇이 잘못되었는지 알아내려고 했습니다. 결국 진짜 디스크가 없으면 내가 만든 디스크를 테스트할 수 없습니다. 테스트할 수 있습니다.
내 A500+를 분해해 보니 가장 흔한 문제 중 하나인 시계 배터리가 도처에서 누출된 것이었습니다. 그래서 나는 이것을 보드에서 제거하고 보드를 청소하기 시작했습니다. 그러는 동안 나는 기계 전체를 꺼내 20년 동안 쌓인 먼지와 때를 청소하기 시작했습니다. 청소를 위해 플로피 드라이브도 분해했습니다.
청소를 하다가 이제 노랗게 변색을 없앨 때가 되었다고 판단되어 레트로브라이트 정보를 따라 해봤습니다.
그런 다음 메인 마더보드의 모든 조인트를 점검한 결과 전원 커넥터의 느슨한 연결, 납땜 인두로 약간의 수정 및 새 것과 같은 것을 발견했습니다. 컴퓨터를 재조립하기 전에 Retr0brite 프로세스에 만족할 때까지 기다렸습니다.
그 동안 나는 디스크 작성을 위한 코드 작업을 계속했습니다. 쓰기 방지 라인의 상태를 읽고 싶었지만 아무리 설정해도 전압이 변하지 않는 것 같았습니다. 그래서 드라이브를 분리하고 쓰기 방지 상태를 감지하는 작은 스위치에서 작은 IC까지의 흔적을 따라갔습니다. 이 시점에서 출력은 실제로 데이터를 쓰고 싶을 때만 사용할 수 있다고 생각했습니다.
많은 후 실험 결과, /WRITE_GATE 쓰기를 활성화하려면 드라이브를 회전하기 전에 핀을 LOW로 설정하십시오. 이 시점에서 쓰기 방지 상태를 얻을 수 있습니다. 또한 /WRITE_GATE 핀이 기본 HIGH 상태로 돌아올 때까지 드라이브가 예전처럼 다시 꺼지지 않았습니다.
Amiga는 한 번에 전체 트랙을 작성합니다. 메모리의 트랙은 11*512바이트(5638바이트)이지만 MFM 인코딩 및 올바른 AmigaDOS 형식을 넣은 후 트랙은 14848바이트로 작동합니다. 글쎄, Arduino의 2k 메모리나 1k의 EEPROM에 들어갈 수 있는 방법은 없습니다. 다른 방법이 필요했습니다.
우선 순위가 높은 스레드에서 데이터를 한 번에 1바이트씩 보내고 다음 바이트를 보내기 전에 Arduino의 응답 바이트를 기다리기로 결정했습니다. 캐릭터간 랙을 줄이기 위해 보드레이트를 2M으로 변경했습니다. 즉, 각 문자를 보내는 데 약 5.5uSec이 소요되고 한 문자를 수신하는 데 5.5uSec이 걸립니다. Arduino는 500khz에서 8비트를 작성해야 하므로 16uSec마다 새 바이트가 필요합니다. 따라서 코드 루프가 충분히 빡빡하고 운영 체제가 송수신을 너무 많이 지연시키지 않는다고 가정하면 시간이 있어야 합니다.
이것은 완전한 실패였습니다. 전체 읽기/쓰기 주기는 디스크 1회전을 훨씬 넘어 너무 오래 걸렸습니다. Arduino 쪽은 아마도 충분히 빠르지 만 OS는 충분히 응답하지 않았습니다. OS(내 경우에는 Windows)가 들어오는 데이터를 버퍼링하기 때문에 디스크 읽기가 작동하지만 쓰기를 하면 Windows는 모든 데이터를 한 번에 보낼 수 있지만 보내는 속도는 Arduino가 필요로 하는 것보다 훨씬 빠르기 때문에 데이터가 손실됩니다. 이것이 제가 이 양방향 승인 절차를 결정한 이유입니다.
데이터 쓰기 - 시도 2
이 애플리케이션의 소프트웨어 흐름 제어는 충분히 빠르지 않았습니다. 하드웨어 흐름 제어를 조사하기로 결정했습니다. FTDI 브레이크아웃 보드에 CTS와 DTR 핀이 있다는 것을 알았습니다. Clear To Send의 약자입니다. 및 데이터 터미널 준비 . 브레이크아웃 보드가 연결되어 있는 동안 아두이노 보드가 CTS를 GND에 연결하는 것을 확인했습니다.

나는 또한 이 핀이 실제로 어느 방향에 있는지 몰랐지만 몇 가지 실험 후에 CTS 핀이 Arduino에서 신호를 받고 PC에서 흐름을 제어하는 데 사용할 수 있다는 것을 발견했습니다. 일반적으로 순환 버퍼를 사용하여 수행되지만 필자의 경우 이를 허용할 수 없으므로 데이터를 원하지 않을 때는 '1'로 설정하고 데이터를 원하지 않을 때는 '0'으로 설정합니다.

이것은 이제 OS에 바이트를 하나의 청크로 대량으로 보내도록 요청할 수 있음을 의미하고 인터럽트가 발생하지 않도록 커널 수준에서 모두 처리되기를 바랍니다.
8비트에서 각 비트를 출력하는 내부 루프가 있었지만 대신 8세트의 명령으로 푸는 것이 더 나은 타이밍이라고 판단했습니다.
작동하지 않았습니다. 실제로 디스크 쓰기 부분을 실행하지 않고 코드를 실행하면 모든 바이트가 올바르게 수신되지만 코드를 실행하면 수신되지 않고 수신된 바이트가 손실됩니다.
CTX 라인의 상태를 변경해도 데이터 흐름이 즉시 중단되지 않고 컴퓨터가 여전히 한두 문자를 보낼 수 있다고 의심했습니다. 아마도 내가 CTX 라인에 신호를 보냈을 땐 이미 다음 문자를 보내는 중이었을 것입니다.
데이터 쓰기 - 시도 3
쓰기 타이밍이 왜곡되는 것을 원하지 않았기 때문에 직렬 인터럽트를 원하지 않았습니다. 각 비트를 플로피 드라이브에 쓰는 사이에 다음 while 루프에 많은 CPU 주기가 있다는 것을 깨달았습니다. CTX가 high가 된 이후 다른 바이트가 수신되었는지 각 비트 쓰기 사이에 확인하고 저장하기로 결정했습니다.
내 이론은 CTX를 올렸을 때 컴퓨터가 이미 다음 바이트를 전송하는 중간에 있었고 스트림 중간에 멈출 수 없기 때문에 이 바이트 후에 절반이 될 것이라는 것입니다. 즉, 루프 중에 하나의 추가 바이트만 확인하고 직렬 포트를 다시 보는 대신 발견하면 사용하면 됩니다.
그래서 이것이 작동하는 것처럼 보였고 Arduino는 컴퓨터에서 데이터를 잃지 않고 쓰기를 완료했습니다. 이제 유일한 질문은 다음과 같습니다. 실제로 데이터를 작성했습니까? 그렇다면 유효한 데이터가 있습니까?
이 시점에서 저는 하나의 트랙만 인코딩했기 때문에 전체 알고리즘을 실행하여 80개의 트랙을 모두 인코딩하기로 결정했습니다. 이상한 일이 일어나고 있었습니다. 드라이브 헤드가 전혀 움직이지 않았습니다. 읽을 때는 여전히 그랬지만 쓸 때는 그렇지 않았습니다.
드라이브 헤드를 앞뒤로 움직이려면 먼저 /WRITE GATE 핀을 올려야 했으며 표면을 변경하는 데도 이것이 필요하다고 생각했습니다. 이 작업을 수행하는 코드를 추가하면 드라이브 헤드가 예상대로 움직였습니다. 이것은 의미가 있었고 머리를 움직이는 동안 트랙을 실수로 쓰는 것을 방지했습니다.
그래서 이 시점에서 이전에 만든 디스크 이미지를 작성한 다음 다시 읽으려고 했습니다. 아무것도 감지할 수 없습니다! 내가 쓴 데이터가 잘못되었거나 쓰는 방식이 잘못되었습니다.
내가 생성하고 있는 것이 정확하고 유효한지 확인하기 위해 독자가 사용하는 섹터 디코딩 알고리즘에 생성 중인 인코딩된 MFM 섹터 데이터를 제공하기로 결정했습니다. 디스크에 데이터를 쓰는 방식에 분명히 문제가 있었습니다.
데이터 쓰기 - 시도 4
데이터가 제대로 읽히지 않았기 때문에 몇 가지 다른 접근 방식을 시도하기로 결정했습니다. /WRITE DATA 핀을 펄스해야 하는지(그렇다면 얼마나 오래), 토글해야 하는지 아니면 원시 데이터 값으로 설정해야 하는지 확신할 수 없었습니다. 내 현재 구현은 핀을 펄스했습니다. 나는 글을 쓸 때 쓰기 핀이 물리적으로 어떻게 조작되었는지에 대한 정보를 온라인에서 찾을 수 없었습니다.
읽기 헤드는 플럭스 반전이 있을 때마다 펄스를 보냅니다. WRITE DATA가 비트 값으로 설정되도록 구현을 변경하기로 결정했습니다. 그것도 작동하지 않았다. 그래서 핀의 현재 상태를 토글하도록 코드를 변경했습니다. 여전히 운이 없습니다.
분명히 이러한 접근 방식 중 하나는 올바른 접근 방식이었을 것입니다. 그래서 나는 무슨 일이 일어나고 있는지 보기 위해 믿을 수 있는 오실로스코프를 다시 꺼내기로 결정했습니다. MFM 패턴 0xAA를 트랙의 모든 바이트에 연속적으로 쓰기로 결정했습니다. 바이너리의 0xAA는 B10101010이므로 필요한 주파수를 모니터링할 수 있는 완벽한 구형파를 제공합니다.
원하는 주파수에서 완벽한 구형파가 보이지 않는다면 일종의 타이밍 문제가 있음을 알았습니다.
스코프를 연결했지만 타이밍이 다음인 것을 보고 놀랐습니다. 완벽한. 그러나 오래된 스코프이기 때문에 몇 개의 펄스 이상을 볼 수 없었습니다. 스코프에는 이 멋진 x10 "mag" 모드가 있습니다. 누르면 타임베이스가 10 증가하지만 더 중요한 것은 최신 디지털 스코프에서처럼 모든 데이터를 스크롤할 수 있다는 점입니다.
여기에서 뭔가 잘못되었습니다. 12비트 정도마다 같았는데 마침 마침표가 "높음"이었습니다. .
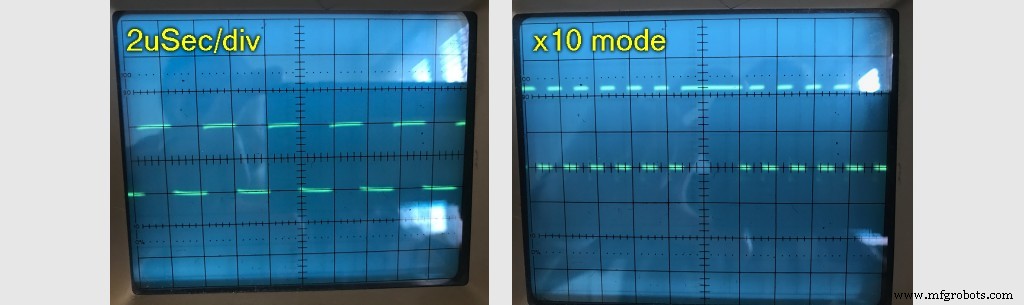
내가 보낸 데이터가 어떤 식으로든 유효하지 않거나 12비트 정도마다 쓰기 프로세스가 일시 중지되는 원인이 있었습니다. 12는 한 바이트에 8비트만 있다는 점을 고려하면 이상한 숫자입니다.
이것에 대해 생각한 후, 나는 흐름 제어 문제로 돌아갔는지 궁금했습니다. 내가 루프를 설계한 방법은 우리가 한 바이트를 기다린 후에 받은 불필요한 추가 바이트를 퍼내는 것이었습니다. 그러나 매 바이트마다 대기를 방지할 만큼 지능적이지 않았습니다. 두 가지 선택이 있었습니다. 무언가를 이동하세요. 인터럽트에 넣거나 루프를 패치합니다.
루프가 먼저 작동하는 방식을 수정하기로 결정했습니다. 이 문제는 컴퓨터에서 다음 바이트를 기다리면서 발생한 지연의 결과였습니다. CTX를 낮추고 1바이트를 기다렸다가 CTX를 다시 올렸을 때 이미 다른 바이트가 진행 중이었습니다.
수신된 두 번째 바이트가 사용되었을 때 Arduino가 일시적으로 CTS를 낮췄다가 다시 높게 설정하여 다른 문자를 보낼 수 있도록 루프를 변경했습니다. 이것은 다음 루프에서 이미 다음 바이트를 받았으므로 기다릴 필요가 없다는 것을 의미합니다.
이것을 테스트하면 완벽한 구형파가 생성되었습니다.
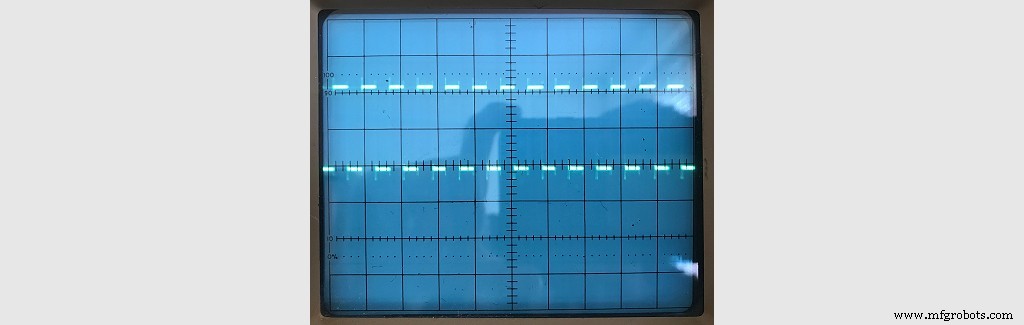
이는 트랙을 작성하기 위한 모든 타이밍이 완벽했으며 실제 쓰고 있던 데이터. 나는 이것을 몇 개의 트랙과 측면에 대해 실행하기로 결정한 다음 올바르게 작성되었는지 확인하기 위해 다시 읽었습니다. /WRITE_DATA 핀을 수신된 데이터의 해당 비트 값으로 설정하고 있었습니다.
데이터를 다시 읽을 때 아무 것도 인코딩되지 않은 것처럼 보였지만 디스크의 반대쪽으로 건너뛰었습니다. 물론 내 패턴이 있었다. 디스크의 한쪽에만 기록된 이유를 알 수 없었습니다.
잠시 생각한 후 /WRITE GATE 핀이 실제로 내가 생각했던 방식으로 작동하지 않는지 궁금해지기 시작했습니다. 핀을 낮추면 드라이브의 지우기 헤드가 활성화될 수 있습니다. 이 경우 실제로 쓸 때만 이 작업을 수행해야 합니다. 그렇지 않으면 디스크가 회전하고 지울 때 소음이 발생할 수 있습니다.
/WRITE GATE는 드라이브를 처음 시작할 때만 사용하고 나중에는 쓰기 루프에서만 문자 그대로 사용하도록 모든 코드를 변경했습니다. 효과가 있었다! 저는 이제 디스크의 양쪽에 데이터를 쓰고 있었습니다!
그래서 실제 ADF 디스크 이미지로 다시 시도하고 완료했습니다. 그런 다음 독자 부분을 사용하여 다시 읽을 수 있는지 확인했습니다. 효과가 있었다! 그러나 어떤 이유로 이 디스크를 다시 읽는 데 꽤 시간이 걸렸습니다. MFM 오류가 발생하지 않았지만 모든 섹터를 찾는 데 어려움을 겪었습니다.
지금 내가 볼 수 있는 두 가지 가능성이 있습니다. 첫째, 데이터가 실제로 적시에 작성되었는지 여부입니다. 둘째, 디스크가 실제 Amiga에서 실제로 작동합니까?
지금 작동 부팅한 디스크를 실제로 작성했을 수도 있다는 생각에 너무 흥분했습니다. A500+를 넣고 디스크를 넣습니다. 잠시 후 디스크가 부팅되기 시작하고 유명한 체크섬 오류 메시지가 표시되었습니다. 그래서 저는 무언가를 쓰고 있었습니다. 유효하지만 일관성이 없었습니다.
훨씬 더 정확한 속도로 데이터를 다시 읽을 수 없다면 디스크를 쓰는 것이 무의미하다고 판단했습니다.
데이터 읽기(다시)
현재 구현에 만족하지 않았기 때문에 읽기 품질을 개선하고 싶었습니다. 현재 구현에서는 펄스가 약간 이상한 시간에 도달하는 데 충분한 유연성을 허용하지 않았습니다. 새로운 접근 방식이 필요했습니다.
먼저 /INDEX 펄스에 읽기를 동기화하기로 결정했습니다. Amiga에서는 필요하지 않지만 나중에 테스트, 쓰기 및 읽기에 유용할 수 있습니다.
이 프로젝트의 전반부에 대한 의견에서 여러 사람들은 내가 구현한 방법보다 펄스 사이의 타이밍을 기록해야 한다고 제안했습니다. 이것의 유일한 문제는 이 데이터를 PC로 충분히 빠르게 가져오는 것이었습니다. 각 비트에 대해 바이트를 보내면 최대 2M 보드를 쉽게 초과할 수 있습니다.
나는 가장 좋은 방법은 데이터를 조금 이해하려고 노력하는 것이라고 결정했습니다. 그래서 원래 사용하던 카운터를 최대 255까지 자유롭게 실행하기로 결정했습니다. 그런 다음 코드를 루프에 넣어 펄스를 기다리며 이 지점에서 시간이 얼마나 흘렀는지 확인했습니다.
이상적인 상황에서 가능한 가장 낮은 최소값은 32(2uSec에 해당)입니다. MFM을 사용하면 연속으로 최대 3개의 0만 가질 수 있으므로 이 값이 도달해야 하는 최대값은 128입니다. 이는 연속적으로 최대 4개의 가능한 조합이 있음을 의미합니다.
이러한 주파수의 대부분이 어디에 있는지 확인하기 위해 여러 디스크를 샘플링했으며 결과는 아래와 같습니다.

이것을 보면 52, 89, 120 카운터 주변에서 포인트의 대부분을 찾을 수 있습니다. 그러나 이것들은 다소 내 드라이브에 특정한 것이므로 좋은 가이드라인이 아닙니다. 몇 가지 실험을 거친 후 다음 공식을 사용했습니다. value =(COUNTER - 16) / 32 . 0과 3 사이에서 잘렸을 때 필요한 출력을 얻었습니다. 이 중 4개마다 1바이트를 쓸 수 있습니다.
MFM으로 인코딩된 비트 스트림에서 두 개의 '1'을 함께 가질 수 없기 때문에 첫 번째 값에 대한 모든 것이 유효하지 않고 또 다른 '01' 시퀀스로 처리될 수 있다고 안전하게 가정할 수 있다는 생각이 들었습니다. 다음 부분은 PC에서 수신한 이 데이터의 압축을 풀고 다시 MFM 데이터로 변환하는 것이었습니다. 00은 발생할 수 없으므로 01은 쓰기 '01'을 의미하고 10은 쓰기 '001'을 의미하고 11은 쓰기 '0001'을 의미하기 때문에 이것은 간단했습니다. 나는 이것을 시도했고 놀랍게도 나의 결과는 100% 성공적이었다. 나는 몇 개의 디스크로 더 시도했습니다. 100%! 이제 매우 안정적인 디스크 리더기를 갖게 되었습니다.
이 새로운 접근 방식이 디스크의 데이터에 대해 훨씬 더 관대해지면서 더 이상 위상 분석이나 많은 재시도가 필요하지 않았습니다. 내 디스크의 대부분은 이제 완벽하게 읽습니다. 일부는 몇 번의 재시도가 필요했지만 결국 거기에 도달했습니다. 마지막 부분은 데이터를 통계적으로 분석하여 복구할 수 있는지 확인하는 것이었지만 잘못된 데이터가 들어오는 경우의 99%는 완전히 인식할 수 없었기 때문에 거의 도움이 되지 않았습니다.
데이터 쓰기 - 5번 시도
이제 내가 작성한 내용을 높은 정확도로 확인할 수 있으므로 작성자를 테스트하는 것이 훨씬 쉬울 것입니다.
무엇이 잘못되었는지 알아보기 위해 코드를 분석하기 시작했습니다. 나는 전체 트랙에 0x55 시퀀스를 쓴 다음 다시 읽었습니다. 때때로 다시 들어오는 데이터에서 비트가 이동했는데, 이는 쓰기에 일종의 타이밍 문제가 있음을 의미합니다.
이것은 부분적으로는 직렬 포트를 처리하는 방식 때문이었고 부분적으로는 타이머를 사용했기 때문인 것으로 나타났습니다. 타이머가 값 32에 도달할 때까지 기다렸다가 비트를 작성한 다음 재설정했습니다. 타이머 카운터 값을 수정할 필요가 없도록 변경했습니다.
카운터가 16에 도달하면 첫 번째 비트를 쓰고 48(16+32)에 도달하면 다음 비트를 쓰고 80(16+32+32)에 도달하면 다음 비트를 쓰는 식입니다. 8비트인 Timer2는 정확히 우리가 필요할 때 8비트 이후에 0으로 롤백됩니다. 이것은 우리가 필요한 타이머 값으로 비트를 쓰는 한 정확히 500kbps가 된다는 것을 의미했습니다.
또한 직렬 포트에서 데이터를 읽는 방법을 살펴보았습니다. 이것은 각 비트 사이에서 읽히고 있었지만 가능한 한 짧아야 했습니다. 약간의 실험 끝에 가장 짧은 작업 블록을 달성했습니다.
확인을 지원하도록 Windows 코드를 수정한 후 이제 다시 시도할 준비가 되었습니다. 이번에는 디스크가 제대로 확인되면 Amiga에서 제대로 작동해야 한다는 것을 알았습니다.
그래서 다른 디스크에 쓰기를 시도했습니다. 확인하면 더 오래 걸렸습니다. 새로운 알고리즘을 사용하면 트랙의 약 95%가 첫 번째 시도에서 검증을 통과했으며 나머지 5%만 다시 한 번 다시 작성해야 합니다. 나는 이것에 만족했고 디스크를 Amiga에 넣었습니다. 완벽하게 작동했습니다!
데이터 쓰기 - 시도 6
이것을 사용해 온 일부 사람들의 피드백 후에 드라이브에 대한 확인을 사용하더라도 완전히 읽을 수 있는 디스크가 항상 생성되지는 않는다는 것이 분명해졌습니다. 소프트웨어는 완벽하게 다시 읽을 수 있지만 Amiga 컴퓨터는 여기저기서 몇 가지 체크섬 오류를 보고합니다.
코드를 다시 살펴보고 타이밍 문제인지 궁금하고 인터럽트 구동되도록 만들 수 있는지 살펴보았지만 슬프게도 각 비트 사이의 짧은 시간으로 인해 인터럽트를 처리할 시간이 충분하지 않습니다. 수정한 레지스터 등을 보존하여 이를 달성하십시오.
그런 다음 작성 코드를 다시 살펴보았습니다. 전체 바이트가 작성된 후 타이머가 0으로 다시 오버플로되기 전에 코드가 루프백되어 다음 바이트를 쓰기 시작했을 수 있으므로 첫 번째 비트가 일찍 작성될 수 있습니다.
이 문제가 있는 사람을 위해 이 문제를 해결할 수 있는 작은 루프를 추가하여 이러한 일이 발생하지 않도록 했습니다.
데이터 쓰기 - 7번 시도
기록된 디스크에 대한 체크섬 오류에 대한 보고를 많이 받은 후 조사를 시작했습니다. 처음에는 디스크에서 MFM 데이터를 살펴봐야 하는 줄 알았는데 실제로는 훨씬 더 간단했습니다.
체크섬 오류를 확인하기 위해 XCopy Pro를 살펴보면 섹터 헤더 및 데이터 영역에서 체크섬 오류를 의미하는 코드 4와 6을 보고했습니다. 그냥 데이터 영역이었다면 트랙의 마지막 몇 비트를 쓰는 것과 관련이 있다고 생각했을 것입니다. 하지만 그렇지 않았습니다.
나는 쓰기 코드와 각 트랙 주위의 패딩을 살펴보기 시작했고, 이따금 트랙의 시작 부분을 덮어쓰고 있는지 궁금해서 포스트 트랙 패딩을 256바이트에서 8바이트로 대폭 줄였습니다. 놀랍게도 내 확인 그런 다음 수많은 오류를 제거했습니다.
이것은 실제 문제가 충분한 데이터를 작성하지 않는 것인지 궁금하게 만들었습니다. Arduino에 Track Erase 명령을 추가하여 전체 트랙에 0xAA 패턴을 작성한 다음 나중에 내 트랙을 작성하도록 설정했습니다. 놀랍게도 XCopy는 100% 엄지손가락을 치켜세웠습니다. 그 문제가 해결되었기를 바랍니다.
진단
나는 이 프로젝트를 성공적으로 만든 사람들로부터 완전히 작동하거나 작동하지 않는 많은 피드백을 받았습니다. 작동하지 않는 사람을 돕기 위해 진단 모듈을 코드에 구축하기로 결정했습니다.
진단 옵션은 Arduino가 처리할 몇 가지 추가 명령과 모든 것이 올바르게 연결되었는지 확인하기 위해 실행되는 일련의 전체 이벤트로 구성됩니다.
다음은 무엇입니까?
전체 프로젝트는 GNU General Public License V3에 따라 무료이며 오픈 소스입니다. 우리가 아미가를 보존할 수 있는 희망을 갖고 싶다면 그 특권을 위해 서로를 찢지 말아야 합니다. 게다가 제가 일한 최고의 플랫폼에 보답하고 싶습니다. 또한 사람들이 이것을 개발하고 더 발전시켜 계속 공유하기를 바랍니다.
현재 쓰기 솔루션은 별도의 FTDI/직렬 브레이크아웃 보드를 사용하지 않는 한 Arduino UNO의 옵션이 아니므로 다음 작업은 해당 보드에서 작동하도록 하는 것입니다(23K256 IC를 사용하여 트랙을 버퍼링한 후 트랙에 쓰기 전에 디스크).
나는 여전히 다른 형식을 보고 싶습니다. ADF 파일은 좋지만 AmigaDOS 형식의 디스크에서만 작동합니다. 이 형식에서 단순히 지원할 수 없는 사용자 지정 복사 방지 및 비표준 섹터 형식이 있는 타이틀이 많이 있습니다. 이에 대한 몇 가지 매우 유용한 정보를 받았지만 현재 테스트할 디스크가 많지 않습니다.
Wikipedia에 따르면 또 다른 디스크 파일 형식인 FDI 형식이 있습니다. 잘 문서화되어 있는 보편적인 형식입니다. 이 형식의 장점은 트랙 데이터를 가능한 한 원본에 가깝게 저장하려고 하므로 위의 문제가 해결되기를 바랍니다!
나는 또한 소프트웨어 보존 협회, 특히 CAPS(공식적으로는 클래식 아미가 보존 협회 ) 및 IPF 형식입니다. 약간의 독서 후에 나는 매우 실망했습니다. 모두 닫혀 있고 디스크 읽기 하드웨어를 판매하기 위해 이 형식을 사용하는 것처럼 느껴졌습니다.
따라서 FDI 형식에 중점을 둘 것입니다. 여기서 나의 유일한 관심사는 데이터 무결성입니다. 읽기가 유효한지 확인하기 위해 확인할 체크섬은 없지만 이를 해결할 몇 가지 아이디어가 있습니다!
<섹션 클래스="섹션 컨테이너 섹션 축소 가능" id="코드">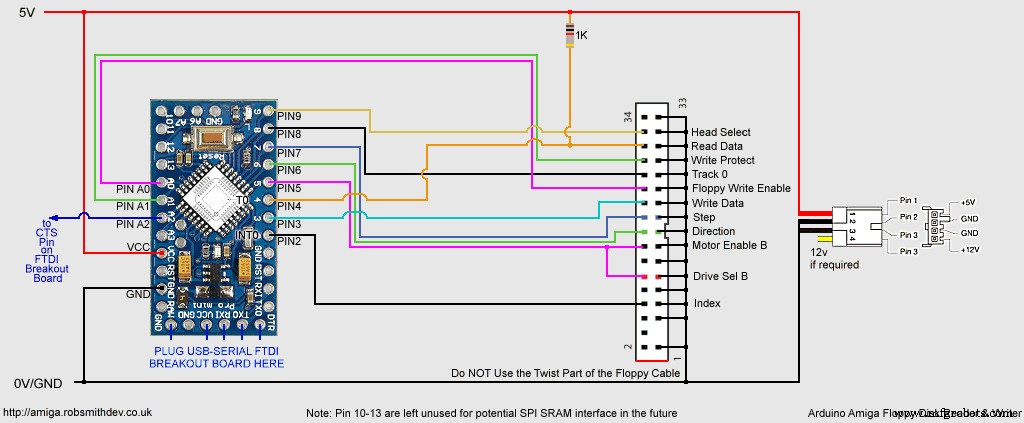 Arduino UNO용 회로
Arduino UNO용 회로 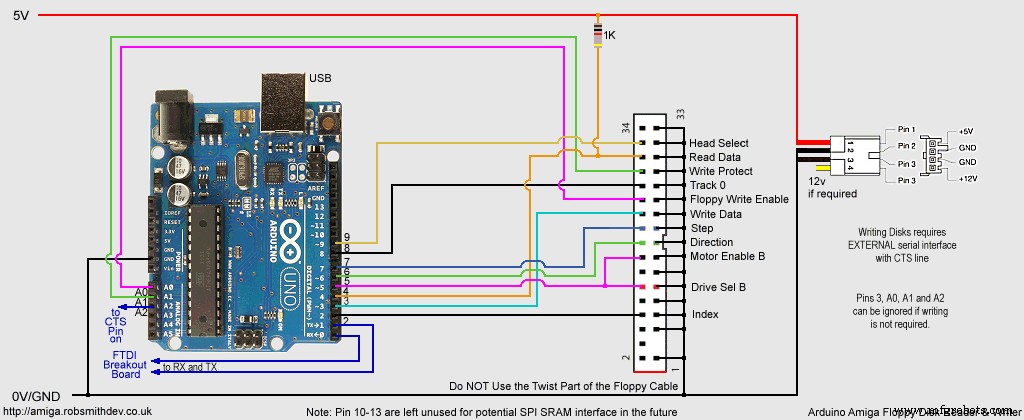
제조공정
구성품 및 소모품 SparkFun esp8266 × 1 Arduino UNO × 1 SparkFun 로직 레벨 변환기 - 양방향 × 1 브레드보드(일반) × 1 점퍼 와이어(일반) × 1 앱 및 온라인 서비스 Arduino IDE circuito.io 펌웨어.ino 소프트웨어 시리얼 이 프로젝트 정보 우리의 목표는 AT 명령(일반적으로 제
구성품 및 소모품 Arduino UNO × 1 SparkFun 330옴 저항기 4개만 필요합니다 × 1 SparkFun 10k 옴 저항기 4개만 필요합니다 × 1 SparkFun 모듬 LED 다른 색상의 LED 4개가 필요합니다. × 1 SparkFun Mini 스피커 사운드에 신경 쓰지 않는다면 이것 없이도 할 수 있습니다. × 1 SparkFun BreadBoard(전체 크기) × 1 점퍼 와이어(일반) × 1