

C 언어

산업 제조
C++ 변수는 명명된 저장 기능을 제공합니다. 그것은 프로그래머가 필요에 따라 데이터를 조작할 수 있습니다. 모든 변수에는 C++의 유형이 있습니다. 변수 유형은 변수 메모리 맵의 크기와 레이아웃, 해당 메모리에 저장할 수 있는 값 범위, 적용할 수 있는 작업 집합을 결정하는 데 도움이 됩니다.
이 C++ 자습서에서는 다음을 배우게 됩니다.
C++ 변수의 기본 유형은 다음과 같습니다.
정수:
정수는 분수 또는 지수 부분이 없는 숫자 리터럴(숫자와 연결됨)입니다. 예시. 120, -90 등
더블:
배정밀도 부동 소수점 값입니다. 예:11.22, 2.345
문자:
문자 리터럴은 작은따옴표 안에 단일 문자를 묶어서 만듭니다. 예:'a', 'm', 'F', 'P', '}' 등
플로트:
부동 소수점 리터럴은 분수 형식이나 지수 형식이 있는 숫자 리터럴입니다. 예:1.3, 2.6
문자열 리터럴:
문자열 리터럴은 큰따옴표로 묶인 일련의 문자입니다. 예:"안녕하세요?"
부울:
부울 값을 true 또는 false로 유지합니다.
다음은 변수 이름 지정에 대한 몇 가지 일반적인 규칙입니다.
C++는 전체 기본 유형 세트를 정의합니다.
무효 type에는 연관된 값이 없으며 몇 가지 상황에서만 사용할 수 있습니다. 값을 반환하지 않는 함수의 반환 유형으로 가장 일반적입니다.
산술 유형 문자, 정수, 부울 값 및 부동 소수점 숫자를 포함합니다. 2개의 범주로 더 나누면 산술 유형
적분 유형 서명되거나 서명되지 않을 수 있습니다.
서명된 유형 :음수 또는 양수(0 포함)를 나타냅니다. 부호 있는 유형에서 범위는 +ve와 -ve 값 사이에 균등하게 나누어져야 합니다. 따라서 8비트 부호 있는 문자는 -127에서 127 사이의 값을 보유합니다.
서명되지 않은 유형 :unsigned 유형에서 모든 값은>=0입니다. 8비트 unsigned char에는 0에서 255(둘 다 포함)가 포함될 수 있습니다.

식별자는 일부 문자, 숫자 및 밑줄 문자 또는 이들의 조합으로 구성될 수 있습니다. 이름 길이에는 제한이 없습니다.
식별자는
// 4개의 다른 int 변수를 정의합니다.
int guru99, gurU99, GuRu99, GURU99;
C++ 언어는 사용을 위해 일부 이름을 예약했습니다.
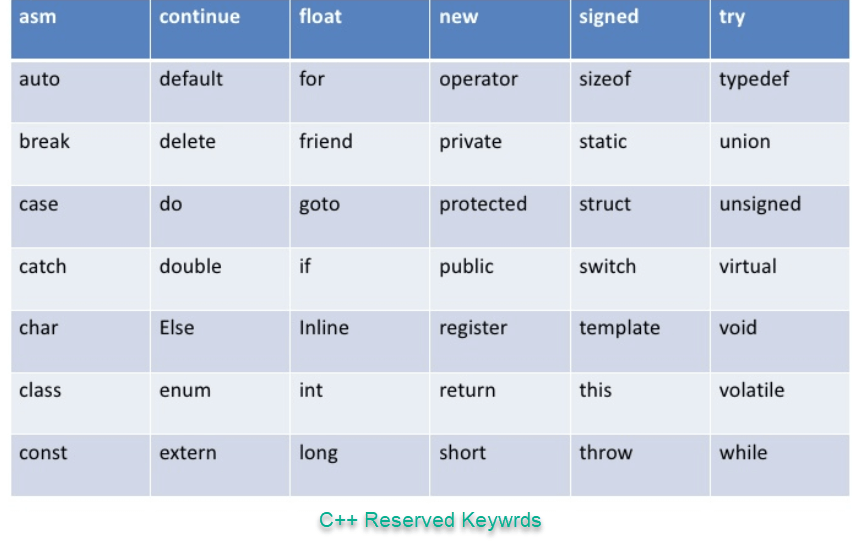
다양한 프로그래밍 언어에서 변수 이름을 지정하는 데 허용되는 규칙이 많이 있습니다. 이러한 규칙을 따르면 프로그램의 가독성을 높일 수 있습니다.
C++ 변수 선언 및 정의
변수 선언은 변수가 정의된 범위에서 프로그램에 이름을 알려줍니다. 예:
int a=5; int b; char c='A';
int a,b; a=b=1000;
List initialization
int a(5);
int b{5}; 사용자로부터 가져올 입력 수를 나타내는 변수 버프 크기가 있다고 가정합니다. 여기서 우리는 프로그램 전체에서 버프 크기의 값을 변경하고 싶지 않습니다. 우리가 알고 있는 값이 변경되어서는 안 되는 변수를 정의하고 싶습니다.
이 경우 키워드 const
를 사용하십시오.const int bufSize = 512; // input buffer size
이것은 bufSize를 상수로 정의합니다. bufSize를 할당하거나 변경하려고 하면 오류가 발생합니다.
여기서 const 객체를 생성한 후에는 값을 변경할 수 없으며 반드시 선언하고 초기화해야 합니다. 그렇지 않으면 컴파일러에서 오류가 발생합니다.
const int i = get_size(); // ok: initialized at run time const int j = 42; // ok: initialized at compile time const int k; // error: k is uninitialized const int i = 42; const int ci = i; // ok: the value in i is copied into ci
범위는 변수에 의미가 있는 프로그램의 범위입니다. 대부분 동일한 이름을 사용하여 다른 범위 내의 다른 엔터티를 참조할 수 있습니다. 변수는 선언된 지점부터 해당 선언이 나타나는 범위의 끝까지 볼 수 있습니다.
#include <iostream>
int main()
{
int sum = 0;
// sum values from 1 through 10 inclusive
for (int val = 1; val <= 10; ++val)
sum += val; // equivalent to sum = sum + val
cout << "Sum of 1 to 10 inclusive is "<< sum <<endl;
return 0;
}
이 프로그램은 viz, main, sum 및 val의 3가지 이름을 정의합니다. std라는 네임스페이스 이름과 해당 네임스페이스의 다른 두 이름인 cout 및 endl을 사용합니다.
중첩 범위
범위는 다른 범위를 포함할 수 있습니다. 포함된(또는 중첩된) 범위를 내부 범위라고 합니다. 포함 범위가 외부 범위입니다.
#include <iostream>
using namespace std;
// Program for illustration purposes only: It is bad style for a function
// to use a global variable and also define a local variable with the same name
int reused = 42; // reused has global scope
int main()
{
int unique = 0; // unique has block scope
// output #1: uses global reused; prints 42 0
cout << reused << " " << unique << endl;
int reused = 0; // new, local object named reused hides global reused
// output #2: uses local reused; prints 0 0
cout << reused << " " << unique << endl;
// output #3: explicitly requests the global reused; prints 42 0
cout << ::reused << " " << unique << endl;
return 0;
}
출력 #1 재사용의 지역 정의 앞에 나타납니다. 따라서 이 출력
문은 전역 범위에서 정의된 재사용된 이름을 사용하는 문입니다. 이 문은
를 출력합니다.42 0
출력 #2 재사용의 로컬 정의 후에 발생합니다. 이제 범위 내에 있습니다. 따라서 이 두 번째 출력 문은 전역 개체가 아닌 재사용이라는 이름의 로컬 개체를 사용하여 출력합니다.
0 0
출력 #3 범위 연산자를 사용하여 기본 범위 지정 규칙을 재정의합니다. 전역 범위에는 이름이 없습니다. 따라서 범위 operator(::)의 왼쪽이 비어 있을 때. 전역 범위의 오른쪽에 있는 이름을 가져오라는 요청으로 해석합니다. 따라서 표현식은 전역 재사용 및 출력을 사용합니다.
42 0
한 유형의 변수는 다른 유형으로 변환될 수 있습니다. "유형 변환"이라고 합니다. 다양한 C++ 변수 유형을 변환하는 규칙을 살펴보겠습니다.
bool이 아닌 변수를 bool 변수에 할당하면 값이 0이면 false가 되고 그렇지 않으면 true가 됩니다.
bool b = 42; // b is true
다른 산술 유형 중 하나에 bool을 할당하면 bool이 참이면 1이, 거짓이면 0이 됩니다.
bool b = true; int i = b; // i has value 1
int 유형의 변수에 부동 소수점 값을 할당하면 값이 잘립니다. 저장되는 값은 소수점 앞부분입니다.
int i = 3.14; // i has value 3
float 유형의 변수에 int 값을 할당하면 소수 부분이 0이 됩니다. 정수에 부동 변수가 수용할 수 있는 것보다 많은 비트가 있으면 정밀도가 일반적으로 손실됩니다.
Int i=3; double pi = i; // pi has value 3.0
범위를 벗어난 값을 부호 없는 유형의 변수에 할당하려고 하면 결과는 값 %(modulo)
의 나머지입니다.예를 들어 8비트 unsigned char 유형은 0에서 255(포함)까지의 값을 보유할 수 있습니다. 이 범위 밖의 값을 할당하면 컴파일러는 나머지 값을 모듈로 256으로 할당하게 됩니다. 따라서 위의 논리에 따라 -1을 8비트 부호 없는 문자에 할당하면 해당 개체에 값 255가 부여됩니다.
unsigned char c = -1; // assuming 8-bit chars, c has value 255
범위를 벗어난 값을 서명된 유형의 개체에 할당하려고 하면 결과를 예측할 수 없습니다. 정의되지 않았습니다. 프로그램이 외부에서 작동하는 것처럼 보이거나 충돌하거나 가비지 값을 생성할 수 있습니다.
signed char c2 = 256; // assuming 8-bit chars, the value of c2 is undefined
컴파일러는 다른 유형의 값이 예상되는 한 유형의 값을 사용할 때 이와 동일한 유형의 변환을 적용합니다.
int i = 42; if (i) // condition will evaluate as true i = 0;
이 값이 0이면 조건은 거짓입니다. 다른 모든(0이 아닌) 값은 true를 반환합니다. 같은 개념으로 산술식에서 bool을 사용하면 그 값은 항상 0 또는 1로 변환됩니다. 결과적으로 산술식에서 bool을 사용하는 것은 일반적으로 거의 틀림이 없습니다.
주의:서명된 유형과 서명되지 않은 유형을 혼합하지 마십시오.
부호 있는 값과 부호 없는 값이 혼합된 표현식은 부호 있는 값이 음수일 때 놀랍고 잘못된 결과를 생성할 수 있습니다. 위에서 논의한 바와 같이 부호 있는 값은 자동으로 부호 없는 값으로 변환됩니다.
예를 들어,
와 같은 산술 표현식에서x* y
x가 -1이고 y가 1이고 x와 y가 모두 int이면 값은 예상대로 -1입니다.
x가 int이고 y가 부호가 없는 경우 이 표현식의 값은 정수가 컴파일 기계에 있는 비트 수에 따라 다릅니다. 우리 컴퓨터에서 이 표현식은 4294967295를 산출합니다.
레지스터 변수는 메모리 변수에 비해 액세스 속도가 더 빠릅니다. 따라서 C++ 프로그램에서 자주 사용되는 변수는 register를 사용하여 레지스터에 넣을 수 있습니다. 예어. register 키워드는 컴파일러에게 주어진 변수를 레지스터에 저장하도록 지시합니다. 레지스터에 넣을지 말지는 컴파일러의 선택입니다. 일반적으로 컴파일러는 일부 변수를 레지스터에 넣는 것을 포함하여 다양한 최적화를 수행합니다. C++ 프로그램에서 레지스터 변수의 수에는 제한이 없습니다. 그러나 컴파일러는 변수를 레지스터에 저장하지 않을 수 있습니다. 레지스터 메모리는 매우 제한적이며 OS에서 가장 일반적으로 사용되기 때문입니다.
정의하려면:
register int i;
댓글
주석은 컴파일러가 무시하는 코드 부분입니다. 프로그래머는 소스 코드/프로그램의 관련 영역에 메모를 작성할 수 있습니다. 주석은 블록 형식이나 한 줄로 제공됩니다. 프로그램 코멘트는 설명문입니다. C++ 코드에 포함될 수 있어 소스 코드를 읽는 데 도움이 됩니다. 모든 프로그래밍 언어는 어떤 형태의 주석을 허용합니다. C++는 한 줄 주석과 여러 줄 주석을 모두 지원합니다.
/* This is a comment */ /* C++ comments can also * span multiple lines */
백스페이스 및 제어 문자와 같은 일부 문자에는 이미지가 표시되지 않습니다. 이러한 문자를 인쇄할 수 없는 문자라고 합니다. 다른 문자(작은따옴표 및 큰따옴표, 물음표 및 백슬래시)는 많은 프로그래밍 언어에서 특별한 의미를 갖습니다.
우리 프로그램은 이러한 문자를 직접 사용할 수 없습니다. 대신, 우리는 이러한 문자를 나타내기 위해 이스케이프 시퀀스를 사용할 수 있습니다. 이스케이프 시퀀스는 백슬래시로 시작합니다.
C++ 프로그래밍 언어는 여러 이스케이프 시퀀스를 정의합니다.
줄 바꿈
\n
세로 탭
\v
백슬래시
\\
캐리지 리턴
\r
가로 탭
\t
백스페이스
\b
물음표
\?
폼피드
\f
경고(벨)
\a
큰따옴표
\”
작은따옴표
\'
마치 단일 문자인 것처럼 이스케이프 시퀀스를 사용합니다.
cout << '\n'; // prints a newline cout << "\tguru99!\n"; // prints a tab followed by "guru99!" and a newline
우리는 또한 일반화된 이스케이프 시퀀스 \x 다음에 하나 이상의 16진수 숫자를 작성할 수 있습니다. 또는 \ 다음에 1, 2 또는 3개의 8진수를 사용합니다. 일반화된 이스케이프 시퀀스는 문자의 숫자 값을 나타냅니다. 몇 가지 예(Latin-1 문자 집합 가정):
\7 (bell) \12 (newline) \40 (blank)
\0 (null) \115 ('M') \x4d ('M')
다른 문자를 사용하는 것처럼 미리 정의된 이스케이프 시퀀스를 사용할 수 있습니다.
cout << "Hi \x4dO\115!\n"; // prints Hi MOM! followed by a newline cout << '\115' << '\n'; // prints M followed by a newline
C 언어
코드 블록을 여러 번 실행해야 하는 상황이 있을 수 있습니다. 일반적으로 명령문은 순차적으로 실행됩니다. 함수의 첫 번째 명령문이 먼저 실행되고 두 번째 명령문이 실행되는 식입니다. 프로그래밍 언어는 더 복잡한 실행 경로를 허용하는 다양한 제어 구조를 제공합니다. 루프문을 사용하면 명령문 또는 명령문 그룹을 여러 번 실행할 수 있으며 다음은 대부분의 프로그래밍 언어에서 루프 명령문의 일반적인 것입니다. − C++ 프로그래밍 언어는 반복 요구 사항을 처리하기 위해 다음과 같은 유형의 루프를 제공합니다. Sr.No 루프 유형 및
C++는 다음 두 가지 유형의 문자열 표현을 제공합니다. - C 스타일 문자열입니다. 표준 C++에 도입된 문자열 클래스 유형입니다. C 스타일 문자열 C 스타일 문자열은 C 언어에서 시작되었으며 C++ 내에서 계속 지원됩니다. 이 문자열은 실제로 null로 끝나는 1차원 문자 배열입니다. 문자 \0. 따라서 null로 끝나는 문자열은 null 뒤에 오는 문자열을 구성하는 문자를 포함합니다. . 다음 선언 및 초기화는 Hello라는 단어로 구성된 문자열을 생성합니다. 배열의 끝에 널 문자를 유지하려면 문자열을 포함하는 문자