

python

산업 제조
정규 표현식(RE) 프로그래밍 언어에서 는 검색 패턴을 설명하는 데 사용되는 특수 텍스트 문자열입니다. 코드, 파일, 로그, 스프레드시트 또는 문서와 같은 텍스트에서 정보를 추출하는 데 매우 유용합니다.
Python 정규식을 사용하는 동안 가장 먼저 인식해야 할 것은 모든 것이 본질적으로 문자이며 문자열이라고도 하는 특정 문자 시퀀스와 일치하는 패턴을 작성한다는 것입니다. ASCII 또는 라틴 문자는 키보드에 있는 문자이며 유니코드는 외래 텍스트와 일치하는 데 사용됩니다. 여기에는 숫자와 구두점 및 $#@!% 등과 같은 모든 특수 문자가 포함됩니다.
이 Python RegEx 자습서에서는 다음을 학습합니다.
예를 들어, Python 정규식은 프로그램이 문자열에서 특정 텍스트를 검색한 다음 그에 따라 결과를 출력하도록 지시할 수 있습니다. 표현식은 다음을 포함할 수 있습니다.
Python의 정규식 또는 RegEx는 RE(RE, regex 또는 regex 패턴)로 표시되며 re 모듈을 통해 가져옵니다. . Python은 라이브러리를 통해 정규식을 지원합니다. Python의 RegEx는 수정자, 식별자 및 공백 문자와 같은 다양한 기능을 지원합니다. .
| 식별자 | 수정자 | 공백 문자 | 이스케이프 필요 |
|---|---|---|---|
| \d=임의의 숫자(숫자) | \d는 숫자를 나타냅니다. 예:\d{1,5} 424,444,545 등과 같이 1,5 사이의 숫자를 선언합니다. | \n =새 줄 | . + * ? [] $ ^ () {} | \ |
| \D=숫자 이외의 모든 것(숫자가 아님) | + =1개 이상과 일치 | \s=공백 | |
| \s =공백 (탭, 공백, 줄 바꿈 등) | ? =0 또는 1과 일치 | \t =탭 | |
| \S=공백 이외의 모든 것 | * =0 이상 | \e =탈출 | |
| \w =문자 ( "_"를 포함한 영숫자 문자 일치) | $ 문자열의 끝과 일치 | \r =캐리지 리턴 | |
| \W =문자 이외의 모든 것( "_"을 제외한 영숫자가 아닌 문자와 일치) | ^ 문자열의 시작 일치 | \f=양식 피드 | |
| . =문자(마침표)를 제외한 모든 것 | | 또는 x/y | 중 하나와 일치합니다.—————— | |
| \b =줄 바꿈을 제외한 모든 문자 | [] =범위 또는 "분산" | —————- | |
| \. | {x} =선행 코드의 양 | —————— |
import re
표현식 (w+) 및 (^)를 사용하여 이 간단한 연습으로 표현식 튜토리얼을 시작할 것입니다.
여기에서 코드에서 w+ 및 ^ 표현식을 사용하는 방법에 대한 Python RegEx 예제를 볼 수 있습니다. 이 튜토리얼의 뒷부분에서 Python의 re.findall() 함수를 다루지만 잠시 동안 \w+ 및 \^ 표현식에만 집중합니다.
예를 들어 "guru99, education is fun"이라는 문자열에 대해 w+ 및^로 코드를 실행하면 "guru99"가 출력됩니다.
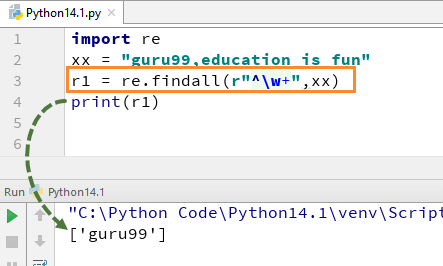
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+",xx) print(r1)
w+에서 +기호를 제거하면 출력이 변경되고 첫 번째 문자의 첫 번째 문자만 표시됩니다. 즉, [g]
Python에서 이 RegEx가 어떻게 작동하는지 이해하기 위해 분할 함수의 간단한 Python RegEx 예제부터 시작합니다. 예에서 우리는 "re.split" 함수를 사용하여 각 단어를 분할했으며 동시에 문자열의 각 단어를 개별적으로 구문 분석할 수 있는 표현식 \s를 사용했습니다.
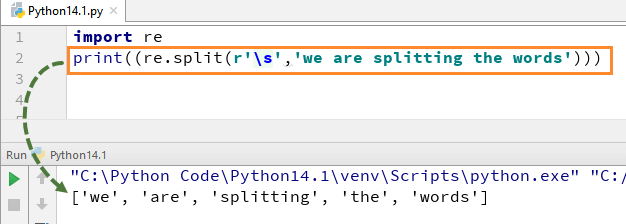
이 코드를 실행하면 ['we', 'are', 'splitting', '', 'words'] 출력이 표시됩니다.
이제 s에서 "\"를 제거하면 어떻게 되는지 살펴보겠습니다. 출력에 '알파벳'이 없습니다. 이는 문자열에서 '\'를 제거하고 "s"를 일반 문자로 평가하여 문자열에서 "s"를 찾을 때마다 단어를 분할하기 때문입니다.
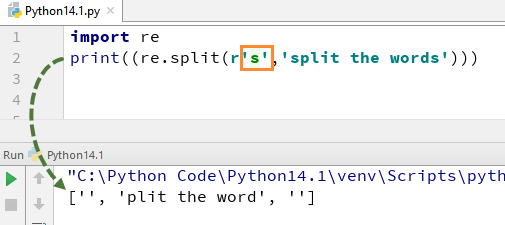
마찬가지로 \d,\D,$,\.,\b 등과 같이 Python에서 다양한 방식으로 사용할 수 있는 일련의 다른 Python 정규식이 있습니다.
전체 코드는 다음과 같습니다.
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+", xx) print((re.split(r'\s','we are splitting the words'))) print((re.split(r's','split the words')))
다음으로 파이썬에서 정규식과 함께 사용되는 메소드의 유형을 살펴보겠습니다.
"re" 패키지는 입력 문자열에 대해 실제로 쿼리를 수행하는 여러 방법을 제공합니다. 우리는 파이썬에서 re의 메소드를 볼 것입니다:
참고 :Python은 정규식을 기반으로 두 가지 기본 작업을 제공합니다. 일치 방법은 문자열의 시작 부분에서만 일치하는지 확인하는 반면 검색은 문자열의 아무 곳에서나 일치하는지 확인합니다.
re.match() Python에서 re의 함수는 정규식 패턴을 검색하고 첫 번째 항목을 반환합니다. Python RegEx Match 메서드는 문자열 시작 부분에서만 일치하는지 확인합니다. 따라서 첫 번째 줄에서 일치 항목이 발견되면 일치 개체를 반환합니다. 그러나 다른 행에서 일치하는 항목이 발견되면 Python RegEx Match 함수는 null을 반환합니다.
예를 들어, Python re.match() 함수의 다음 코드를 고려하십시오. "w+" 및 "\W"라는 표현은 문자 'g'로 시작하는 단어와 일치하며 그 이후에는 'g'로 시작하지 않는 단어는 식별되지 않습니다. 목록 또는 문자열의 각 요소에 대한 일치를 확인하기 위해 이 Python re.match() 예제에서 forloop를 실행합니다.
re.search() 함수는 정규식 패턴을 검색하고 첫 번째 항목을 반환합니다. Python re.match()와 달리 입력 문자열의 모든 행을 검사합니다. Python re.search() 함수는 패턴이 발견되면 일치 객체를 반환하고 패턴을 찾지 못하면 "null"을 반환합니다.
search() 함수를 사용하려면 먼저 Python re 모듈을 가져온 다음 코드를 실행해야 합니다. Python re.search() 함수는 "패턴"과 "텍스트"를 사용하여 기본 문자열에서 스캔합니다.
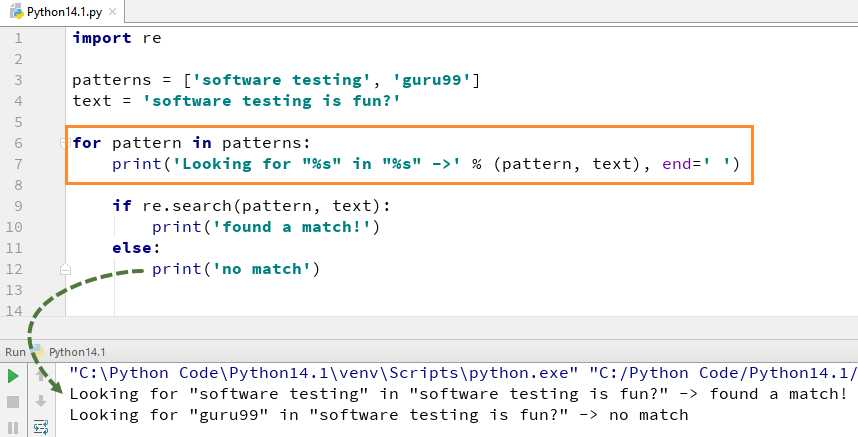
예를 들어 여기에서 "Software Testing is fun"이라는 텍스트 문자열에서 "Software testing" "guru99"라는 두 개의 리터럴 문자열을 찾습니다. "소프트웨어 테스트"의 경우 일치하는 항목을 찾았으므로 Python re.search() 예제의 출력을 "일치하는 항목을 찾았습니다"로 반환하는 반면 "guru99"라는 단어의 경우 문자열에서 찾을 수 없으므로 출력을 "일치하는 항목 없음"으로 반환합니다. ".
findall() 모듈은 주어진 패턴과 일치하는 "모든" 항목을 검색하는 데 사용됩니다. 대조적으로 search() 모듈은 지정된 패턴과 일치하는 첫 번째 항목만 반환합니다. findall()은 파일의 모든 줄을 반복하고 단일 단계에서 겹치지 않는 모든 패턴 일치 항목을 반환합니다.
여기에 이메일 주소 목록이 있고 모든 이메일 주소를 목록에서 가져오기를 원합니다. Python에서 re.findall() 메서드를 사용합니다. 목록에서 모든 이메일 주소를 찾습니다.
다음은 re.findall()
예제의 전체 코드입니다.import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print((z.groups()))
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ')
if re.search(pattern, text):
print('found a match!')
else:
print('no match')
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print(email) 많은 Python Regex 메서드 및 Regex 함수는 플래그라는 선택적 인수를 사용합니다. 이 플래그는 주어진 Python Regex 패턴의 의미를 수정할 수 있습니다. 이를 이해하기 위해 이러한 플래그의 한 두 가지 예를 볼 수 있습니다.
Python에서 사용되는 다양한 플래그는 다음을 포함합니다.
| Regex 플래그의 구문 | 이 플래그의 기능 |
|---|---|
| [re.M] | 시작/끝이 각 줄을 고려하도록 설정 |
| [re.I] | 대소문자 무시 |
| [re.S] | [ . ] |
| [re.U] | { \w,\W,\b,\B}가 유니코드 규칙을 따르도록 합니다. |
| [re.L] | {\w,\W,\b,\B}가 로케일을 따르도록 합니다. |
| [re.X] | 정규식에서 주석 허용 |
여러 줄에서 패턴 문자 [^]는 문자열의 첫 번째 문자와 각 줄의 시작과 일치합니다(각 줄 바꿈 바로 다음에 옴). 반면 작은 "w"는 공백을 문자로 표시하는 데 사용됩니다. 코드를 실행할 때 첫 번째 변수 "k1"은 단어 guru99에 대한 문자 'g'만 인쇄하는 반면, 여러 줄 플래그를 추가하면 문자열의 모든 요소의 첫 번째 문자를 가져옵니다.
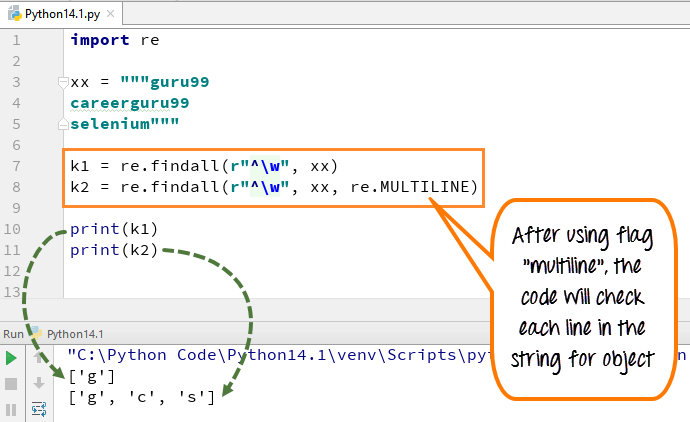
코드는 다음과 같습니다.
import re xx = """guru99 careerguru99 selenium""" k1 = re.findall(r"^\w", xx) k2 = re.findall(r"^\w", xx, re.MULTILINE) print(k1) print(k2)
마찬가지로 re.U(유니코드), re.L(로케일 따르기), re.X(주석 허용) 등과 같은 다른 Python 플래그를 사용할 수도 있습니다.
위의 코드는 Python 3 예제이며, Python 2에서 실행하려면 다음 코드를 고려하십시오.
# Example of w+ and ^ Expression
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+",xx)
print r1
# Example of \s expression in re.split function
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+", xx)
print (re.split(r'\s','we are splitting the words'))
print (re.split(r's','split the words'))
# Using re.findall for text
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print(z.groups())
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print 'Looking for "%s" in "%s" ->' % (pattern, text),
if re.search(pattern, text):
print 'found a match!'
else:
print 'no match'
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print email
# Example of re.M or Multiline Flags
import re
xx = """guru99
careerguru99
selenium"""
k1 = re.findall(r"^\w", xx)
k2 = re.findall(r"^\w", xx, re.MULTILINE)
print k1
print k2
프로그래밍 언어의 정규식은 검색 패턴을 설명하는 데 사용되는 특수 텍스트 문자열입니다. 여기에는 숫자와 구두점 및 $#@!% 등과 같은 모든 특수 문자가 포함됩니다. 표현식에는 리터럴이 포함될 수 있습니다.
Python에서 정규식은 Python re 모듈을 통해 포함된 RE(RE, regexes 또는 regex 패턴)로 표시됩니다.
python
Pillow Python Imaging Library는 이미지 처리에 이상적입니다. 일반적으로 보관 및 일괄 처리 응용 프로그램에 사용됩니다. 물론, 생각할 수 있는 다른 용도로 자유롭게 사용할 수 있습니다. 라이브러리를 사용하여 다음을 수행할 수 있습니다. 썸네일 만들기 파일 형식 간 변환, 이미지 인쇄 Fet 히스토그램(자동 대비 향상에 이상적) 이미지 회전 흐림 효과와 같은 필터 적용 목차 이미지 처리 패키지 설치 이미지 처리 중 이미지 표시 추가 정보 이미지 처리 패키지 설치 Pillow를 설치하려면 원래 Pyth
Python 생태계에서 생각할 수 있는 거의 모든 것을 위한 패키지가 있으며, 모두 간단한 pip 명령으로 설치할 수 있습니다. 따라서 Python에도 이모티콘을 사용할 수 있는 패키지가 있다는 사실에 놀라지 마세요. 다음을 사용하여 이모티콘 패키지를 설치할 수 있습니다. $ pip3 install emoji 이 패키지를 사용하면 유니코드 이모티콘을 문자열 버전으로 또는 그 반대로 변환할 수 있습니다. import emoji result = emoji.emojize(Python is :thumbs_up:) print(result