Python XML Parser Tutorial:xml 파일 읽기 예제(Minidom, ElementTree)
XML이란 무엇입니까?
XML은 eXtensible Markup Language의 약자입니다. 중소량의 데이터를 저장 및 전송하도록 설계되었으며 구조화된 정보를 공유하는 데 널리 사용됩니다.
Python을 사용하면 XML 문서를 구문 분석하고 수정할 수 있습니다. XML 문서를 구문 분석하려면 전체 XML 문서가 메모리에 있어야 합니다. 이 튜토리얼에서는 Python에서 XML minidom 클래스를 사용하여 XML 파일을 로드하고 구문 분석하는 방법을 살펴봅니다.
이 튜토리얼에서 배울 것입니다-
minidom을 사용하여 XML을 구문 분석하는 방법
XML 노드 생성 방법
ElementTree를 사용하여 XML을 구문 분석하는 방법
minidom을 사용하여 XML을 구문 분석하는 방법
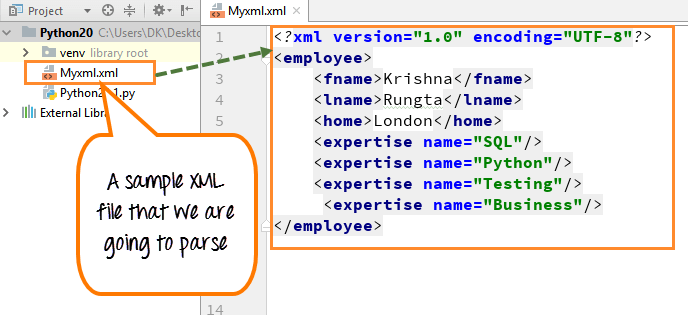
구문 분석할 샘플 XML 파일을 만들었습니다.
1단계) 파일 내부에서 이름, 성, 집 및 전문 분야(SQL, Python, 테스팅 및 비즈니스)를 볼 수 있습니다.
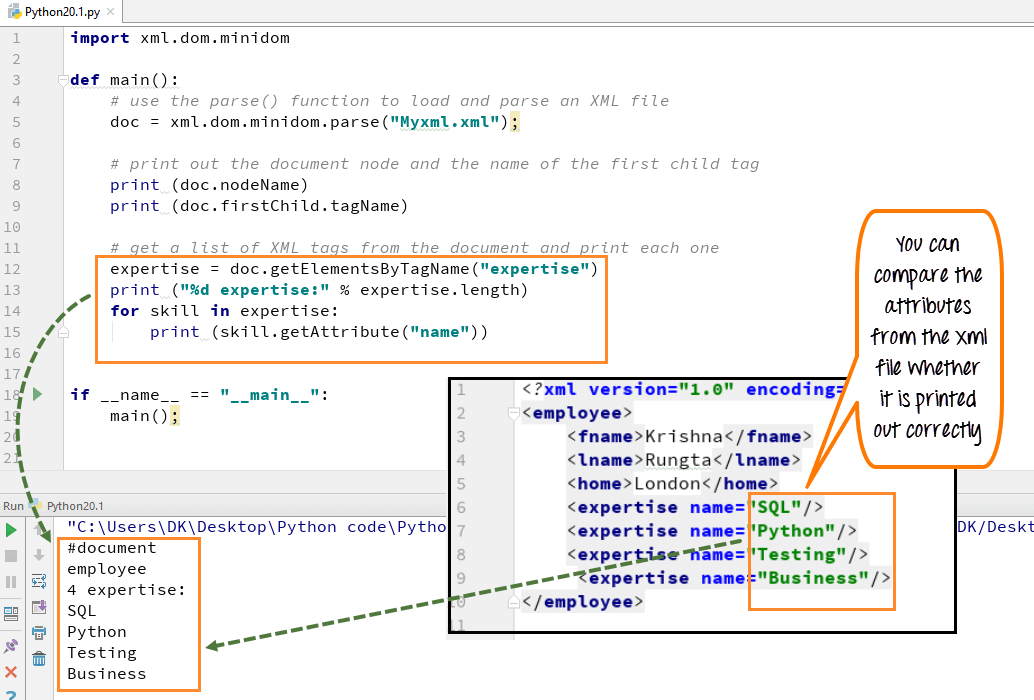
2단계) 문서를 구문 분석하면 "노드 이름"을 인쇄합니다. 문서 루트 및 "firstchild tagname" . 태그 이름과 노드 이름은 XML 파일의 표준 속성입니다.
xml.dom.minidom 모듈을 임포트하고 파싱되어야 하는 파일(myxml.xml)을 선언
이 파일에는 이름, 성, 집, 전문 지식 등과 같은 직원에 대한 몇 가지 기본 정보가 들어 있습니다.
XML 미니돔의 구문 분석 기능을 사용하여 XML 파일을 로드하고 구문 분석합니다.
우리는 doc 변수를 가지고 있고 doc는 구문 분석 함수의 결과를 얻습니다.
파일에서 노드 이름과 자식 태그 이름을 인쇄하고 싶으므로 인쇄 함수에서 선언합니다.
코드 실행 - XML 파일의 노드 이름(#document)과 XML 파일의 첫 번째 자식 태그 이름(직원)을 출력합니다.
참고 :
Nodename 및 자식 tagname은 XML dom의 표준 이름 또는 속성입니다. 이러한 유형의 명명 규칙에 익숙하지 않은 경우
3단계) XML 문서에서 XML 태그 목록을 호출하여 인쇄할 수도 있습니다. 여기에서 SQL, Python, 테스트 및 비즈니스와 같은 기술 세트를 인쇄했습니다.
변수 전문 지식을 선언합니다. 여기서 직원 이름이 가지고 있는 모든 전문 지식을 추출할 것입니다.
"getElementsByTagName"이라는 dom 표준 함수 사용
스킬이라는 이름의 모든 요소를 가져옵니다.
각 스킬 태그에 대해 루프 선언
코드 실행 - 네 가지 기술 목록이 표시됩니다.
XML 노드 생성 방법
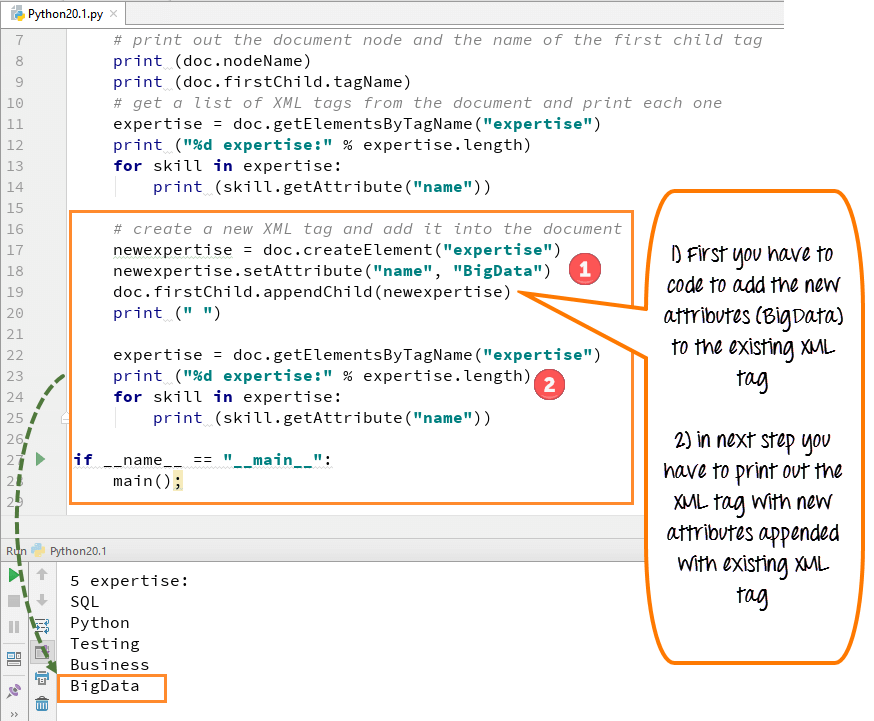
"createElement" 함수를 사용하여 새 속성을 만든 다음 이 새 속성 또는 태그를 기존 XML 태그에 추가할 수 있습니다. XML 파일에 새 태그 "BigData"를 추가했습니다.
기존 XML 태그에 새 속성(BigData)을 추가하려면 코딩해야 합니다.
그런 다음 기존 XML 태그에 새 속성이 추가된 XML 태그를 인쇄해야 합니다.
새 XML을 추가하고 문서에 추가하려면 "doc.create elements" 코드를 사용합니다.
이 코드는 "빅 데이터"라는 새 속성에 대한 새 기술 태그를 생성합니다.
문서의 첫 번째 자식(직원)에 이 기술 태그 추가
코드 실행 - 새로운 태그 "빅 데이터"가 다른 전문 지식 목록과 함께 나타납니다.
XML 파서 예
Python 2 예제
import xml.dom.minidom
def main():
# use the parse() function to load and parse an XML file
doc = xml.dom.minidom.parse("Myxml.xml");
# print out the document node and the name of the first child tag
print doc.nodeName
print doc.firstChild.tagName
# get a list of XML tags from the document and print each one
expertise = doc.getElementsByTagName("expertise")
print "%d expertise:" % expertise.length
for skill in expertise:
print skill.getAttribute("name")
# create a new XML tag and add it into the document
newexpertise = doc.createElement("expertise")
newexpertise.setAttribute("name", "BigData")
doc.firstChild.appendChild(newexpertise)
print " "
expertise = doc.getElementsByTagName("expertise")
print "%d expertise:" % expertise.length
for skill in expertise:
print skill.getAttribute("name")
if name == "__main__":
main();
Python 3 예제
import xml.dom.minidom
def main():
# use the parse() function to load and parse an XML file
doc = xml.dom.minidom.parse("Myxml.xml");
# print out the document node and the name of the first child tag
print (doc.nodeName)
print (doc.firstChild.tagName)
# get a list of XML tags from the document and print each one
expertise = doc.getElementsByTagName("expertise")
print ("%d expertise:" % expertise.length)
for skill in expertise:
print (skill.getAttribute("name"))
# create a new XML tag and add it into the document
newexpertise = doc.createElement("expertise")
newexpertise.setAttribute("name", "BigData")
doc.firstChild.appendChild(newexpertise)
print (" ")
expertise = doc.getElementsByTagName("expertise")
print ("%d expertise:" % expertise.length)
for skill in expertise:
print (skill.getAttribute("name"))
if __name__ == "__main__":
main();
ElementTree를 사용하여 XML을 구문 분석하는 방법
ElementTree는 XML을 조작하기 위한 API입니다. ElementTree는 XML 파일을 처리하는 쉬운 방법입니다.
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# all items data
print('Expertise Data:')
for elem in root:
for subelem in elem:
print(subelem.text)
출력:
Expertise Data:
SQL
Python
요약:
Python을 사용하면 한 번에 한 줄만이 아니라 전체 XML 문서를 한 번에 구문 분석할 수 있습니다. XML 문서를 구문 분석하려면 전체 문서가 메모리에 있어야 합니다.
XML 문서를 구문 분석하려면
xml.dom.minidom 가져오기
"parse" 기능을 사용하여 문서 구문 분석( doc=xml.dom.minidom.parse(파일 이름);
코드를 사용하여 XML 문서에서 XML 태그 목록 호출(=doc.getElementsByTagName( "name of xml tags")