

산업용 로봇

산업 제조
Python 신경망을 개발하려는 경우 올바른 위치에 있습니다. Excel을 사용하여 네트워크에 대한 교육 데이터를 개발하는 방법에 대한 이 기사의 논의를 자세히 살펴보기 전에 배경 정보에 대해 아래 시리즈의 나머지 부분을 확인하는 것이 좋습니다.
<올>
실제 시나리오에서 훈련 샘플은 신경망이 이 모든 정보를 일관된 입출력 관계로 일반화하는 데 도움이 되는 "솔루션"과 결합된 일종의 측정 데이터로 구성됩니다.
예를 들어, 신경망이 색상, 모양 및 밀도를 기반으로 토마토의 섭식 품질을 예측하기를 원한다고 가정해 보겠습니다. 색상, 모양 및 밀도가 전반적인 맛과 얼마나 정확히 관련되는지는 모르지만 할 수 있습니다. 색상, 모양 및 밀도를 측정하면 합니다. 미뢰가 있다. 따라서 수천 개의 토마토를 수집하고 관련 물리적 특성을 기록하고 각 토마토(가장 좋은 부분)를 맛본 다음 이 모든 정보를 테이블에 입력하기만 하면 됩니다.
각 행은 내가 하나의 훈련 샘플이라고 부르는 것이며 4개의 열이 있습니다. 이 중 3개(색상, 모양 및 밀도)는 입력 열이고 네 번째는 목표 출력입니다.
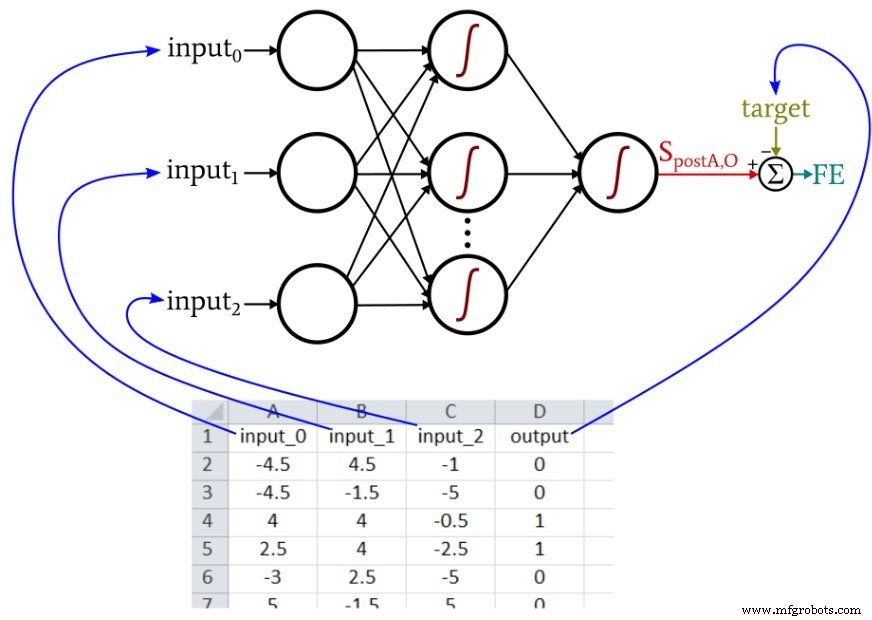
훈련하는 동안 신경망은 세 개의 입력 값과 출력 값 사이의 관계(일관된 관계가 존재하는 경우)를 찾습니다.
모든 것은 숫자 형식으로 처리되어야 함을 명심하십시오. "plum-shaped" 문자열을 신경망에 대한 입력으로 사용할 수 없으며 "군침이 도는" 문자열은 출력 값으로 작동하지 않습니다. 측정 및 분류를 수량화해야 합니다.
모양의 경우 각 토마토에 -1에서 +1 사이의 값을 할당할 수 있습니다. 여기서 -1은 완전한 구형을 나타내고 +1은 매우 길쭉한 것을 나타냅니다. 먹는 품질의 경우 각 토마토를 "먹을 수 없음"에서 "맛있게 먹을 수 있음"에 이르는 5점 척도로 평가한 다음 원-핫 인코딩을 사용하여 평가를 5개 요소 출력 벡터에 매핑할 수 있습니다.
다음 다이어그램은 이러한 유형의 인코딩이 신경망 출력 분류에 사용되는 방식을 보여줍니다.
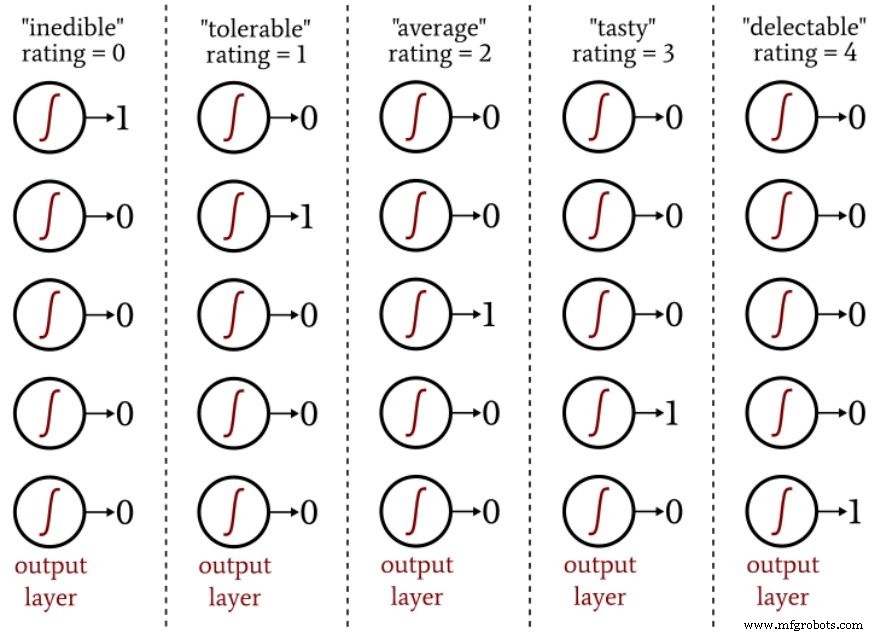
원-핫 출력 방식을 사용하면 로지스틱-시그모이드 활성화와 호환되는 방식으로 이진이 아닌 분류를 수량화할 수 있습니다. 로지스틱 함수의 출력은 출력 값이 최소 또는 최대에 매우 가까운 입력 값의 무한 범위에 비해 곡선의 전환 영역이 좁기 때문에 본질적으로 이진법입니다.
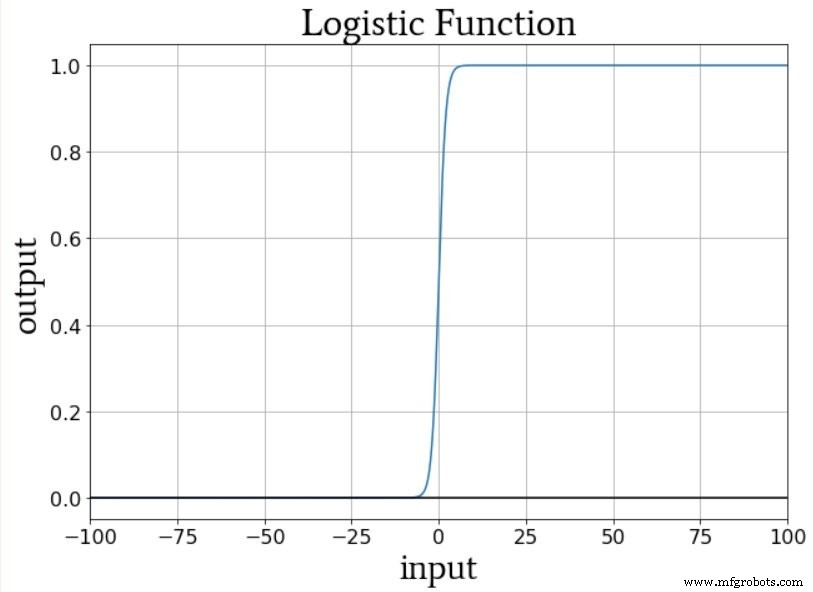
따라서 이 네트워크를 단일 출력 노드로 구성한 다음 출력 값이 0, 1, 2, 3 또는 4(0, 0.2, 0.4, 0.6 또는 0.8)인 훈련 샘플을 제공하고 싶지 않습니다. 0 대 1 범위에 머물고 싶다면); 출력 노드의 로지스틱 활성화 함수는 최소 및 최대 등급을 강력하게 선호합니다.
신경망은 모든 토마토가 먹을 수 없거나 맛있다고 결론짓는 것이 얼마나 터무니없는 일인지 이해하지 못합니다.
12부에서 논의한 Python 신경망은 Excel 파일에서 훈련 샘플을 가져옵니다. 이 예에서 사용할 교육 데이터는 다음과 같이 구성됩니다.
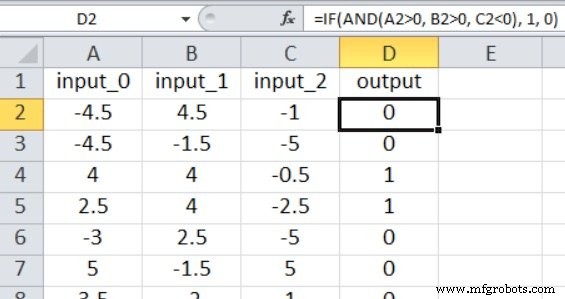
현재 Perceptron 코드는 하나의 출력 노드로 제한되어 있으므로 우리가 할 수 있는 일은 참/거짓 유형의 분류를 수행하는 것뿐입니다. 입력 값은 다음 Excel 공식을 사용하여 생성된 –5와 +5 사이의 임의의 숫자입니다.
=RANDBETWEEN(-10, 10)/2
스크린샷과 같이 출력은 다음과 같이 계산됩니다.
=IF(AND(A2>0, B2>0, C2<0), 1, 0)
따라서 출력은 input_0이 0보다 크고, input_1이 0보다 크며, input_2가 0보다 작은 경우에만 참입니다. 그렇지 않으면 거짓입니다.
이것은 Perceptron이 훈련 데이터에서 추출해야 하는 수학적 입력-출력 관계입니다. 원하는 만큼 샘플을 생성할 수 있습니다. 이와 같은 간단한 문제의 경우 샘플 5000개와 Epoch 1개로 매우 높은 분류 정확도를 달성할 수 있습니다.
입력 차원을 3으로 설정해야 합니다(I_dim =3, 내 변수 이름을 사용하는 경우). 네 개의 숨겨진 노드(H_dim =4), 학습률 0.1(LR =0.1).
training_data =pandas.read_excel(...) 찾기 명세서를 입력하고 스프레드시트의 이름을 삽입하십시오. (엑셀에 접근할 수 없는 경우 Pandas 라이브러리도 ODS 파일을 읽을 수 있습니다.) 그런 다음 실행 버튼을 클릭하면 됩니다. 2.5GHz Windows 노트북에서 5,000개의 샘플을 사용하여 교육하는 데 몇 초밖에 걸리지 않습니다.
파트 12에 포함된 완전한 "MLP_v1.py" 프로그램을 사용하는 경우 유효성 검사(다음 섹션 참조)는 교육이 완료된 직후 시작되므로 네트워크를 교육하기 전에 유효성 검사 데이터를 준비해야 합니다. .
네트워크의 성능을 검증하기 위해 두 번째 스프레드시트를 만들고 정확히 동일한 공식을 사용하여 입력 및 출력 값을 생성한 다음 훈련 데이터를 가져오는 것과 같은 방식으로 이 검증 데이터를 가져옵니다.
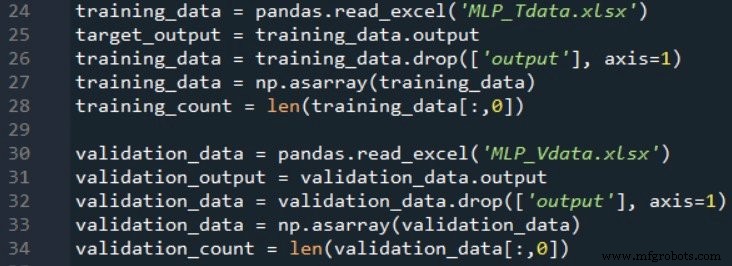
다음 코드 발췌는 기본 유효성 검사를 수행하는 방법을 보여줍니다.
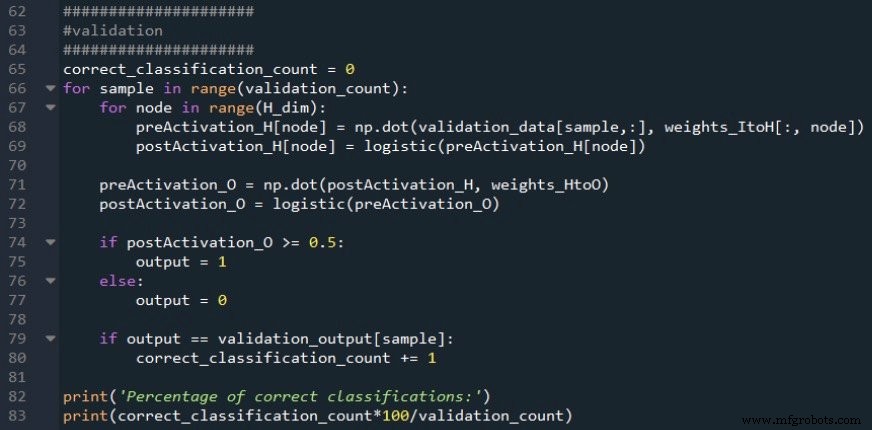
표준 피드포워드 절차를 사용하여 출력 노드의 활성화 후 신호를 계산한 다음 if/else 문을 사용하여 활성화 후 값을 참/거짓 분류 값으로 변환하는 임계값을 적용합니다.
분류 정확도는 분류 값을 현재 검증 샘플의 목표 값과 비교하여 올바른 분류 수를 세고 검증 샘플 개수로 나누어 계산합니다.
np.random.seed(1) 명령어가 주석 처리되면 가중치는 프로그램을 실행할 때마다 다른 임의의 값으로 초기화되며 결과적으로 분류 정확도가 한 실행에서 다음 실행으로 변경됩니다. 위에 지정된 매개변수, 5000개의 훈련 샘플 및 1000개의 검증 샘플을 사용하여 15개의 개별 실행을 수행했습니다.
가장 낮은 분류 정확도는 88.5%, 최고는 98.1%, 평균은 94.4%였습니다.
우리는 신경망 훈련 데이터와 관련된 몇 가지 중요한 이론적 정보를 다루었고 파이썬 언어 다층 퍼셉트론으로 초기 훈련 및 검증 실험을 했습니다. 신경망에 대한 AAC 시리즈를 즐기시기 바랍니다. 첫 번째 기사 이후로 많은 진전이 있었고 아직 논의해야 할 것이 훨씬 더 많습니다!
산업용 로봇
용접공은 오늘날 제조 인력의 필수적인 부분입니다. 점점 더 많은 용접이 자동화됨에 따라 이러한 용접공은 용접 자체의 기술을 배우는 것이 아니라 용접 로봇을 작동하는 훈련이 필요합니다. 업계에서 성공하는 데 필요한 용접 로봇 교육을 받기 위해 취할 수 있는 경로는 다양합니다. 용접기가 용접 응용 프로그램을 완료하기 위해 로봇뿐만 아니라 용접 토치를 사용하도록 훈련할 수 있는 여러 곳이 있습니다. Education-Portal.com에 따르면 미국 전역의 커뮤니티, 기술 대학 및 종합 대학은 현재 로봇 공학 과정을 포함하는 용접 기술
안전은 로봇 산업 자동화를 고려할 때 주요 관심사입니다. 정확하고 생산적이며 신뢰할 수 있는 로봇은 귀중한 산업 근로자입니다. 그러나 작업자가 잘못된 시간에 작업 영역에 들어가면 심각하거나 치명적인 사고를 일으킬 수 있을 만큼 강력하고 빠릅니다. 잘 훈련된 사용자가 적절하게 설치한 로봇은 모든 사람을 보호하는 데 필요한 모든 안전 기능을 갖추고 있습니다. 2013년에 로봇 산업 협회는 1999년 이후 처음으로 로봇에 대한 안전 요구 사항(ANSI/RIA R15.06-2012)을 업데이트했습니다. 업데이트는 미국의 제조업체와 사용자