새로운 하이브리드 데이터 흐름 및 Von Neumann 아키텍처는 다음을 포함한 워크로드를 가속화할 수 있습니다. 신경망, 기계 학습, 컴퓨터 비전, DSP 및 기본 선형 대수 하위 프로그램.
실리콘 밸리의 신생 기업인 Quadric은 로봇, 공장 자동화 및 의료 영상과 같은 에지 장치를 위한 AI 및 표준 컴퓨터 비전 알고리즘 워크로드를 모두 가속화하도록 설계된 가속기를 구축했습니다. 회사의 하드웨어 아키텍처는 신경망, 기계 학습, 컴퓨터 비전, DSP 및 기본 선형 대수 하위 프로그램을 포함한 워크로드를 처리할 수 있는 새로운 하이브리드 데이터 흐름 및 Von Neumann 설계입니다.
Quadric의 CEO인 Veerbhan Kheterpal은 EE Times 에 "처음부터 AI가 에지 장치의 온디바이스 컴퓨팅에 필요한 유일한 애플리케이션이 아니라는 사실을 잘 알고 있었습니다."라고 말했습니다. . “이 제품의 개발자는 전체 시스템이 AI와 함께 고전적인 고성능 컴퓨팅 알고리즘을 실행할 수 있어야 합니다. 이것이 바로 전체 시스템 요구 사항입니다.”
Kheterpal은 아키텍처가 개별 워크로드를 위한 가속기 모음이 아니라고 강조했습니다. 오히려 AI 추론을 포함하여 다양한 워크로드를 가속화하도록 설계된 데이터 병렬 명령어 세트가 포함된 통합 아키텍처입니다.
Quadric의 최고 제품 책임자인 Daniel Firu는 "최근 AI가 움직이고 있는 곳에서는 전체 레이어를 FFT(고속 푸리에 변환)로 대체하는 흥미로운 추세가 있습니다. Quadric은 연구원들이 일부 레이어를 FFT로 교체하여 변압기 네트워크를 가속화한 Google의 최근 논문을 인용하면서 이러한 유형의 워크로드를 가속화하기 위해 자리를 잡았습니다. Google은 BERT 벤치마크에서 92%의 정확도를 달성한 네트워크를 생성하기 위해 변압기 인코더의 self-attention 하위 계층을 FFT로 대체했습니다. 훈련 속도는 GPU에서 최대 7배, Google TPU에서 2배 더 빨랐습니다.
Quadric의 개발자 키트, Q16 프로세서 및 4GB 외부 메모리가 탑재된 M.2 카드(출처:Quadric)
포도원 로봇
Quadric의 3명의 공동 설립자 Veerbhan Kheterpal, Daniel Firu 및 Nigel Drego는 이전에 Coinbase에 매각된 비트코인 채굴 회사인 21을 설립했습니다. Quadric, Burlingame, CA는 칩 설계를 시작하지 않았습니다. 대신 원래 Napa Valley 포도밭을 오르락내리락하며 포도나무를 바라보고 관개 누수나 해충을 발견하면 경고를 보낼 수 있는 농업용 로봇을 만들었습니다.
Veerbhan Kheterpal(출처:Quadric)
Kheterpal은 "이를 구축할 때 드론 공급망에서 5~10,000달러에 구축된 실행 가능한 제품이 아니라는 것을 깨달았습니다."라고 말했습니다. “50,000달러의 비용이 드는 트랙터 공급망에서 구축해야 하고 GPU가 탑재된 대형 PC와 수많은 카메라를 탑재해야 합니다. 그 때 우리는 모든 로봇 공학 소프트웨어의 내부를 살펴보고 Nvidia 및 Intel과 같은 플랫폼에서 이러한 에너지 수요를 증가시켜야 하는 근본적인 원인을 발견했습니다.”
회사는 Firu에 따르면 "우리가 원했던 칩"인 가속기 칩을 구축하는 데 주력했습니다.
2017년에 시드 펀딩 라운드가 시작되었고, Quadric의 주요 투자자인 일본 자동차 Tier-One Denso를 비롯한 잠재 고객으로부터 1,300만 달러를 창출한 시리즈 A 라운드가 이어졌습니다. Quadric의 총 자금은 1,800만 달러입니다.
튜링 완료
Quadric은 데이터 흐름 아키텍처에서 요소를 가져와 Von Neumann 기계의 요소와 결합하는 명령 기반 아키텍처를 사용합니다. 목표는 에지 장치의 이기종 시스템을 덜 복잡한 것으로 교체하는 것입니다. Turing의 완전한 기계인 Quadric Vortex 코어는 가속과 유연성의 조합을 제공한다고 회사는 주장합니다. 아키텍처는 코어 어레이 측면에서 확장 가능하며 고급(7 또는 5nm) 프로세스 노드로 이식 가능합니다. 이는 전력 예산이 약 수백 밀리와트에서 20W 사이인 에지 장치 애플리케이션에 적합합니다.
회사의 첫 번째 칩인 Q16은 16 x 16 Vortex 코어 어레이입니다. 각 코어에는 행렬 곱셈 및 AI 계산을 수행할 수 있는 기능이 있지만 각 코어에는 AND, OR, 감소, 시프트 등과 같은 연산을 위한 다기능 ALU도 있습니다. 소프트웨어를 통해 개발자는 LSTM 활성화 기능 등을 포함한 다양한 알고리즘 유형을 표현할 수 있습니다. If-Then-Else 문은 전체 어레이에서 사용할 수 있으므로 개발자는 세분화된 희소성을 활용할 수 있습니다.
어레이의 각 코어에는 인접 코어에 대한 단일 주기 액세스와 4Kb의 코어 내 메모리에 대한 단일 주기 액세스가 있습니다. 온칩 메모리도 어레이와 함께 포함되어 코어에 대기 시간이 짧고 결정적 액세스를 제공합니다.
코어는 Quadric이 "단일 명령, 다중 디코딩" 방식이라고 부르는 방식으로 병렬로 작동합니다. 각 코어는 모든 주기에서 동일한 명령을 받습니다. 그러나 런타임 시 동적 데이터를 기반으로 각 코어는 해당 명령어를 다르게 해석할 수 있습니다. 이를 통해 코어 또는 코어 그룹이 약간 다른 기능을 수행할 수 있습니다.
또한 대역폭을 어레이로 최적화하고 신경망 가중치와 같은 상수를 한 번에 모든 코어로 브로드캐스트하는 데 사용할 수 있는 전용 브로드캐스트 버스가 포함되어 있습니다(Firu는 많은 컴퓨터 비전 알고리즘에도 루프 불변 정보가 있다고 말했습니다. 버스에 매핑됨).
동적 정보는 결정적 커널 런타임을 허용하는 정적 소프트웨어 제어 로드 저장 장치를 통해 어레이에 입력됩니다. 이 장치는 장치의 모든 두 가장자리에서 동시에 로드 및 저장할 수 있으며 신경망 가중치를 보내는 데 사용할 수 있는 한 가장자리에서 특수 속성을 허용합니다. 두 가장자리에서 로드하고 세 번째 가장자리에서 동시에 저장하면 컴퓨팅 실행 런타임을 줄일 수 있습니다.
다니엘 피루(출처:Quadric)
Firu는 "한 면에 적재한 다음 수직면에서 보관할 수 있습니다."라고 말했습니다. “이를 통해 소프트웨어 수준에서 꽤 흥미로운 일들이 일어날 수 있습니다. 또한 이 패러다임을 사용하여 데이터 재매핑 및 이미지 회전과 같은 작업을 시작할 수 있습니다.”
한편, 소프트웨어 제어 정적 메모리(캐시 아님) 온칩은 대규모 데이터 구조를 위한 공간을 제공합니다. Quadric은 개발자가 내부에서 임의의 데이터 구조를 정의할 수 있도록 API 액세스를 허용합니다. Q16 칩의 메모리는 8GB로 "HD에서 2~3개의 프레임 버퍼 또는 전체 가중치 신경망"에 적합하다고 Firu는 말했습니다.
소프트웨어 스택
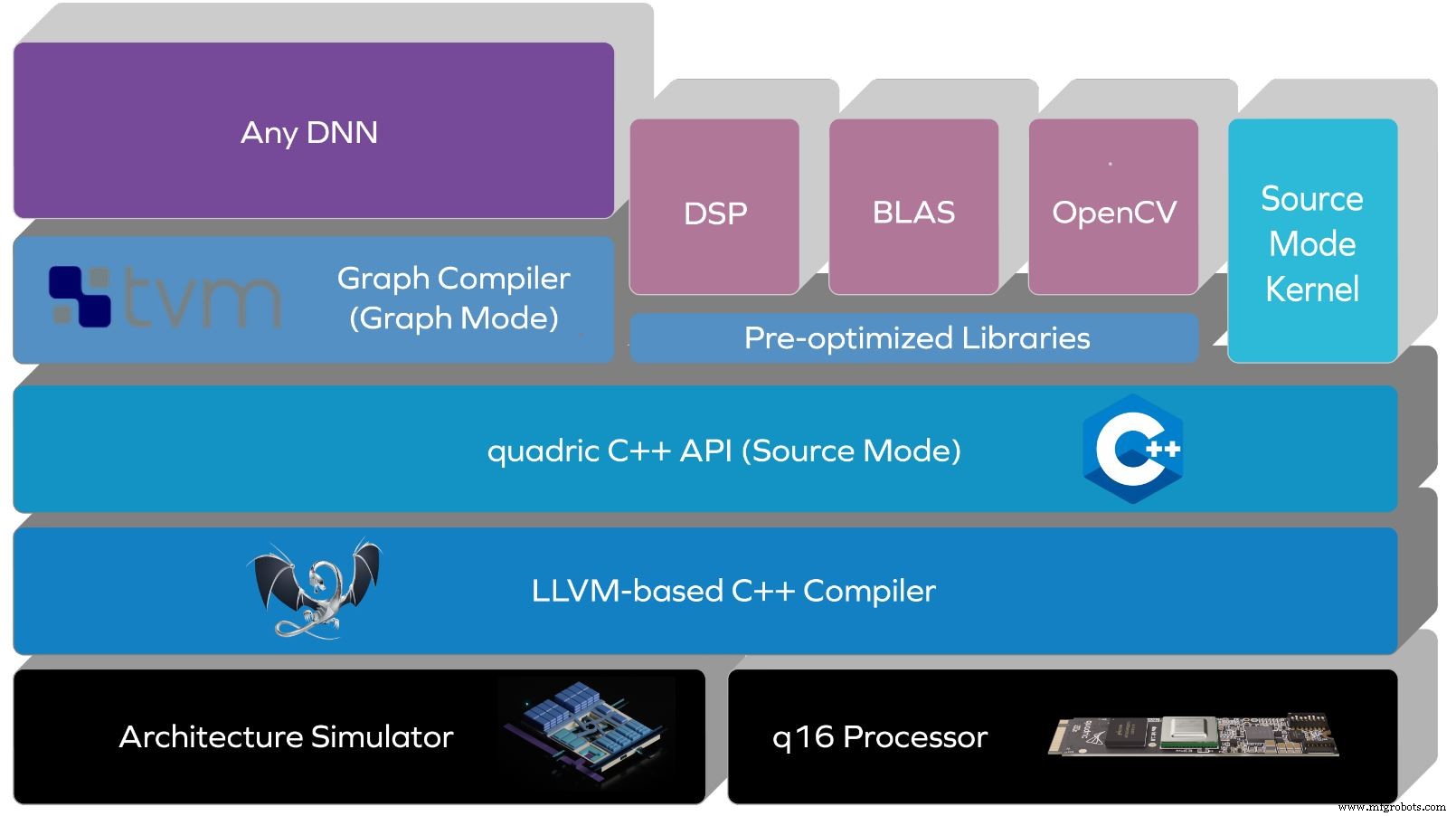
Quadric은 실리콘보다 먼저 소프트웨어 스택을 구축했습니다. 고객은 회사의 아키텍처 시뮬레이터 또는 FPGA와 함께 1년 동안 이를 사용해 왔다고 Kheterpal은 말했습니다. Quadric의 스택은 C++ API가 맨 위에 있는 LLVM 기반 컴파일러를 통해 아키텍처와 명령어 세트를 추상화합니다.
소스 모드는 프로세서의 아키텍처 기능에 대한 소스 수준 C++ 제어를 통해 다양한 데이터 병렬 알고리즘을 지원합니다. 신경망이 더욱 복잡해짐에 따라 개발자는 소스 모드를 통해 사용자 지정 작업을 표현할 수도 있습니다.
Quadric의 소프트웨어 스택(출처:Quadric)
스택에 대한 향후 업데이트는 TensorFlow 또는 ONNX 버전의 신경망을 지원하는 코드 없는 그래프 모드를 제공할 것입니다. 여기에는 자동으로 코드를 생성하는 TVM 기반 심층 신경망(DNN) 컴파일러가 포함됩니다.
Kheterpal은 "우리는 코드 없는 기능과 고유한 사용자 지정 코드를 가질 수 있는 유연성을 결합하고 흥미로운 방식으로 결합하여 응용 프로그램을 달성하고 있습니다."라고 말했습니다. “대부분의 플랫폼은 일종의 DNN 컴파일러가 있는 AI 전용 아키텍처만 제공합니다. 하지만 사용자 지정은 어떻습니까? 지원되지 않는 DNN은 어떻습니까? 지원되지 않는 연산자는 어떻게 됩니까? 이것은 Turing 완전한 코어이기 때문에 이러한 제한이 없습니다. 코어는 모든 작업을 수행할 수 있습니다. 코드 유연성을 통해 개발자는 원하는 알고리즘을 작성할 수 있습니다."
칩 로드맵
16nm 실리콘의 16 x 16 어레이에 256개의 Vortex 코어가 있는 Quadric의 Q16 칩은 4개의 INT8 DNN TOPS를 제공합니다. 초당 200개의 추론으로 ResNet-50을 실행할 수 있으며(224 x 224 이미지 크기에서 INT8 매개변수의 경우) 평균 2W를 소비합니다.
Quadric의 로드맵에는 2세대 아키텍처와 Q32 칩(1,000개 코어 어레이)의 테이프아웃이 포함되며 "아마도 7nm"라고 Firu는 말했습니다. Q16은 엄격히 가속기(시스템 호스트 프로세서와 나란히 위치)이지만 개발 중인 Q32에는 호스트 역할을 하는 Arm 또는 RISC-V 코어도 포함될 수 있습니다.
Q16의 범용 메모리 공간에 직접 매핑되는 4GB의 외부 메모리와 함께 Q16 프로세서가 포함된 M.2 형식 개발자 키트를 지금 사용할 수 있습니다.