

임베디드

산업 제조
Perceptron 신경망에 대한 AAC 시리즈에 오신 것을 환영합니다. 배경 지식을 처음부터 시작하거나 앞으로 나아가고 싶다면 여기에서 나머지 기사를 확인하세요.
<올>이전 기사에서는 신경망 기반 신호 처리의 관점에서 조사한 간단한 분류 작업을 소개했습니다. 이 작업에 필요한 수학적 관계는 너무 단순해서 특정 가중치 집합이 어떻게 출력 노드가 입력 데이터를 올바르게 분류할 수 있는지 생각하는 것만으로도 네트워크를 설계할 수 있었습니다.
이것은 내가 설계한 네트워크입니다:
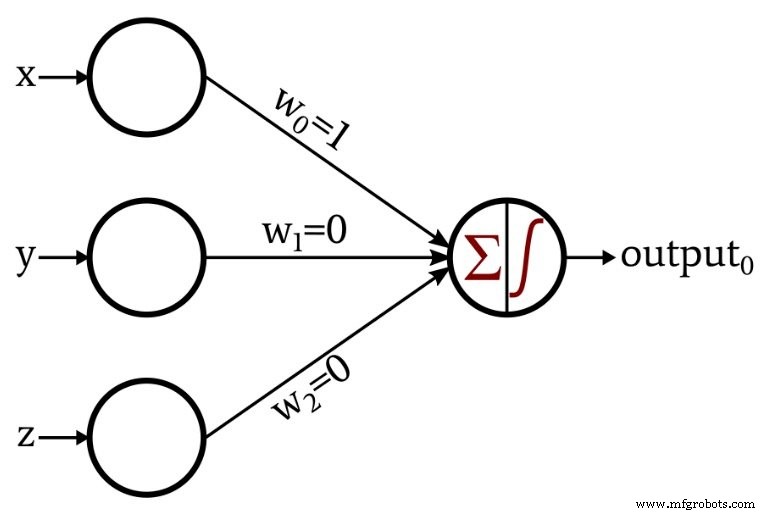
출력 노드의 활성화 함수는 단위 단계입니다.
\[f(x)=\begin{cases}0 &x <0\\1 &x \geq 0\end{cases}\]
교육이라는 절차를 통해 자체 가중치를 생성하는 네트워크를 제시했을 때 토론이 좀 더 흥미로워졌습니다.
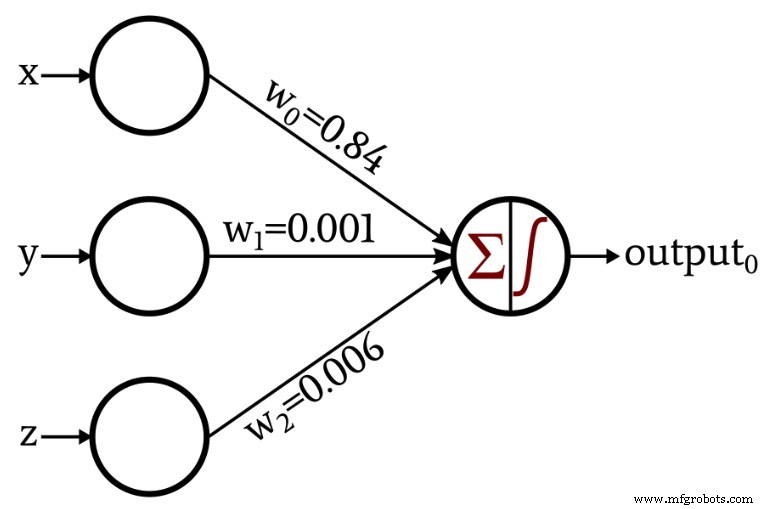
이 기사의 나머지 부분에서는 이러한 가중치를 얻는 데 사용한 Python 코드를 살펴보겠습니다.
코드는 다음과 같습니다.
<사전>판다 수입 numpy를 np로 가져오기 input_dim =3 learning_rate =0.01 가중치 =np.random.rand(input_dim) #가중치[0] =0.5 #가중치[1] =0.5 #가중치[2] =0.5 Training_Data =pandas.read_excel("3D_data.xlsx") 예상_출력 =교육_데이터.출력 Training_Data =Training_Data.drop(['출력'], 축=1) Training_Data =np.asarray(Training_Data) training_count =len(교육_데이터[:,0]) 범위(0,5)의 신기원:범위(0, training_count)의 데이터:Output_Sum =np.sum(np.multiply(Training_Data[데이텀,:], 가중치)) Output_Sum <0인 경우:출력 값 =0 또 다른:출력 값 =1 오류 =예상_출력[데이텀] - 출력_값 범위(0, input_dim)의 n:가중치[n] =가중치[n] + learning_rate*error*Training_Data[datum,n] print("w_0 =%.3f" %(가중치[0])) print("w_1 =%.3f" %(가중치[1])) print("w_2 =%.3f" %(가중치[2]))
이 지침을 자세히 살펴보겠습니다.
input_dim =3
차원을 조정할 수 있습니다. 우리의 입력 데이터는 3차원 좌표로 구성되어 있으므로 3개의 입력 노드가 필요합니다. 이 프로그램은 다중 출력 노드를 지원하지 않지만 조정 가능한 출력 차원을 향후 실험에 통합할 예정입니다.
학습 속도 =0.01
학습률에 대해서는 향후 기사에서 다루겠습니다.
가중치 =np.random.rand(input_dim) #가중치[0] =0.5 #가중치[1] =0.5 #가중치[2] =0.5
가중치는 일반적으로 임의의 값으로 초기화됩니다. numpy random.rand() 함수는 input_dim 길이의 배열을 생성합니다. 간격 [0, 1)에 걸쳐 분포된 임의의 값으로 채워집니다. 그러나 초기 가중치 값은 훈련 절차에서 생성된 최종 가중치 값에 영향을 미치므로 다른 변수(예:훈련 세트 크기 또는 학습률)의 효과를 평가하려면 모든 무작위로 생성된 숫자 대신 알려진 상수에 가중치를 둡니다.
교육_데이터 =pandas.read_excel("3D_data.xlsx") 팬더 라이브러리를 사용하여 Excel 스프레드시트에서 교육 데이터를 가져옵니다. 다음 기사에서는 훈련 데이터에 대해 더 자세히 알아볼 것입니다.
<사전>예상_출력 =교육_데이터.출력 Training_Data =Training_Data.drop(['출력'], 축=1)훈련 데이터 세트에는 입력 값과 해당 출력 값이 포함됩니다. 첫 번째 명령은 출력 값을 분리하여 별도의 배열에 저장하고, 다음 명령은 훈련 데이터 세트에서 출력 값을 제거합니다.
<사전>교육_데이터 =np.asarray(교육_데이터) training_count =len(Training_Data[:,0])현재 pandas 데이터 구조인 학습 데이터 세트를 numpy 배열로 변환한 다음 열 중 하나의 길이를 보고 학습에 사용할 수 있는 데이터 포인트 수를 결정합니다.
범위(0,5)의 에포크:
한 교육 세션의 길이는 사용 가능한 교육 데이터 수에 따라 결정됩니다. 그러나 동일한 데이터 세트를 사용하여 네트워크를 여러 번 훈련하여 가중치를 계속 최적화할 수 있습니다. 네트워크에서 이미 이러한 훈련 데이터를 봤다고 해서 훈련의 이점이 사라지는 것은 아닙니다. 전체 훈련 세트를 완전히 통과할 때마다 에포크(epoch)라고 합니다.
범위(0, training_count)의 데이터:
이 루프에 포함된 절차는 훈련 세트의 각 행에 대해 한 번 발생합니다. 여기서 "행"은 입력 데이터 값의 그룹과 해당 출력 값을 나타냅니다(이 경우 입력 그룹은 x, y를 나타내는 3개의 숫자로 구성됨). , 및 3차원 공간에서 점의 z 구성요소).
출력 합계 =np.sum(np.multiply(Training_Data[datum,:], 가중치))
출력 노드는 세 개의 입력 노드에서 전달한 값을 합산해야 합니다. 내 Python 구현은 먼저 Training_Data 배열의 요소별 곱셈을 수행하여 이를 수행합니다. 및 가중치 배열을 선택한 다음 해당 곱셈으로 생성된 배열의 요소 합계를 계산합니다.
<사전>Output_Sum <0인 경우:출력 값 =0 또 다른:Output_Value =1if-else 문은 단위 단계 활성화 함수를 적용합니다. 합계가 0보다 작으면 출력 노드에 의해 생성된 값은 0입니다. 합이 0보다 크거나 같으면 출력 값은 1입니다.
첫 번째 출력 계산이 완료되면 가중치 값이 있지만 무작위로 생성되기 때문에 분류에 도움이 되지 않습니다. 입력 데이터와 원하는 출력 값 사이의 수학적 관계를 점진적으로 반영하도록 가중치를 반복적으로 수정하여 신경망을 효과적인 분류 시스템으로 전환합니다. 가중치 수정은 훈련 세트의 각 행에 대해 다음 학습 규칙을 적용하여 수행됩니다.
\[w_{new} =w+(\alpha\times(출력_{예상}-출력_{계산})\times 입력)\]
기호 \( \alpha \) 학습률을 나타냅니다. 따라서 새로운 가중치 값을 계산하기 위해 해당 입력 값에 학습률을 곱하고 예상 출력(훈련 세트에서 제공)과 계산된 출력 간의 차이를 곱한 다음 이 곱의 결과를 더합니다. 현재 무게 값으로. 델타(\(\delta\) )를 (\(output_{expected} - output_{calculated}\))로 다시 작성할 수 있습니다.
\[w_{new} =w+(\alpha\times\delta\times 입력)\]
이것이 제가 Python에서 학습 규칙을 구현한 방법입니다:
<사전>오류 =예상_출력[데이텀] - 출력_값 범위(0, input_dim)의 n:가중치[n] =가중치[n] + learning_rate*error*Training_Data[datum,n]
이제 단일 계층, 단일 출력 노드 Perceptron을 훈련하는 데 사용할 수 있는 코드가 있습니다. 신경망 훈련의 이론과 실습에 대한 자세한 내용은 다음 기사에서 살펴보겠습니다.
임베디드
모든 제조 관리자는 숙련된 CNC 기계 작업자를 적절한 수로 찾고 고용하는 것이 거의 불가능하다는 것을 알고 있습니다. 결과적으로 기업은 경험이 없는 사람들을 생산적인 수준으로 끌어올리기 위해 자체 교육 방법을 개발하고 있습니다. 저의 혼합 학습 접근 방식은 교육 요구 사항을 해결하기 위해 강의실 교육, 현장 교육 및 외부 리소스를 결합합니다. 경험 많은 사람들이 커리큘럼을 준비하고 전달하는 데 소비하는 시간을 최소화하려면 외부 리소스를 사용하여 교육의 기반을 제공하는 동시에 사내 강의실과 회사별 문제에 대한 현장 교육을 예약하십
제품 제조에서 제품의 내구성과 미관을 위한 가장 중요한 공정 중 하나는 아노다이징 공정입니다. 이 프로세스는 여러 재료에 이상적이지만 가장 중요하고 일반적으로 사용되는 재료는 알루미늄입니다. 기계가공의 초심자라면 아노다이징에 익숙하지 않고 알루미늄 아노다이징 방법은 말할 것도 없을 것입니다. 따라서 이 가이드에서는 알루미늄 아노다이징에 대해 알아야 할 모든 것을 안내합니다. 이것은 무엇을, 어떻게 알루미늄을 아노다이징하는지, 알루미늄을 아노다이징하는 이유에 대해 살펴보는 형식입니다. 양극 처리된 알루미늄이란 무엇입니까 ? 아노