

임베디드

산업 제조
C 언어의 공용체를 사용하여 데이터를 압축하고 압축을 푸는 방법에 대해 알아보세요.
이전 기사에서 우리는 공용체의 원래 응용 프로그램이 상호 배타적인 변수를 위한 공유 메모리 영역을 생성하는 것이라고 논의했습니다. 그러나 시간이 지남에 따라 프로그래머는 완전히 다른 응용 프로그램에 대해 공용체를 널리 사용했습니다. 즉, 더 큰 데이터 개체에서 더 작은 데이터 부분을 추출하는 것입니다. 이 기사에서는 이러한 특정 조합의 적용을 더 자세히 살펴보겠습니다.
공용체의 구성원은 공유 메모리 영역에 저장됩니다. 이것이 노동조합에 대한 흥미로운 신청서를 찾을 수 있게 해주는 핵심 기능입니다.
아래의 조합을 고려하십시오.
union { uint16_t 단어; 구조체 { uint8_t 바이트1; uint8_t 바이트2; };} u1; 이 공용체에는 두 개의 구성원이 있습니다. 첫 번째 구성원인 "word"는 2바이트 변수입니다. 두 번째 멤버는 두 개의 1바이트 변수 구조입니다. 공용체에 할당된 2바이트는 두 구성원 간에 공유됩니다.
할당된 메모리 공간은 아래 그림 1과 같을 수 있습니다.
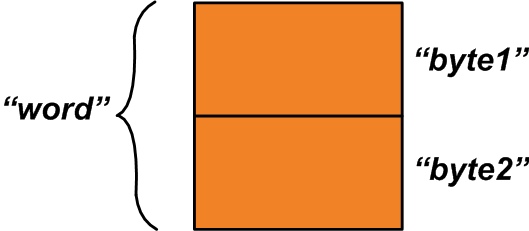
"word" 변수가 할당된 전체 메모리 공간을 나타내는 반면 "byte1" 및 "byte2" 변수는 "word" 변수를 구성하는 1바이트 영역을 나타냅니다. 이 기능을 어떻게 사용할 수 있습니까? 단일 2바이트 변수를 생성하기 위해 결합되어야 하는 두 개의 1바이트 변수 "x"와 "y"가 있다고 가정합니다.
이 경우 위의 공용체를 사용하여 다음과 같이 구조체 멤버에 "x"와 "y"를 할당할 수 있습니다.
u1.byte1 =y;u1.byte2 =x; 이제 유니온의 "단어" 멤버를 읽어 "x" 및 "y" 변수로 구성된 2바이트 변수를 얻을 수 있습니다(그림 2 참조).
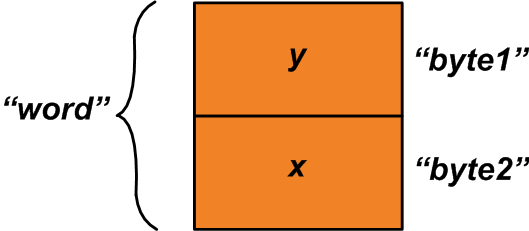
위의 예는 두 개의 1바이트 변수를 단일 2바이트 변수로 패킹하기 위한 공용체 사용을 보여줍니다. 반대의 경우도 있습니다. 2바이트 값을 "word"에 쓰고 "x" 및 "y" 변수를 읽어 두 개의 1바이트 변수로 압축을 풉니다. Union의 한 구성원에게 값을 쓰고 다른 구성원을 읽는 것을 때때로 "data punning"이라고 합니다.
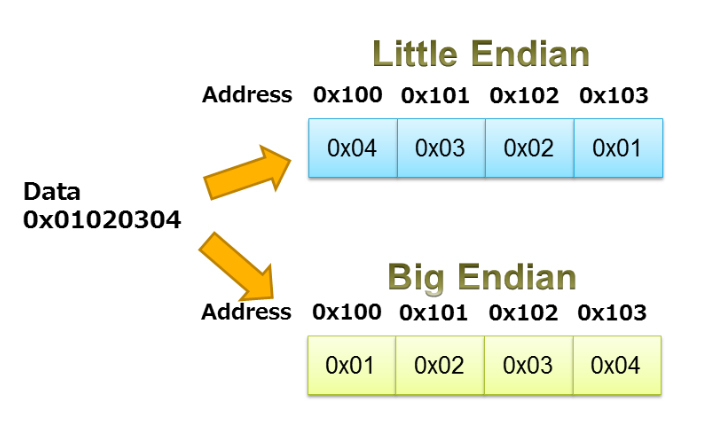
데이터 패킹/언패킹을 위해 공용체를 사용할 때 프로세서 엔디안(endianness)에 주의해야 합니다. 엔디안(endianness)에 대한 Robert Keim의 기사에서 논의된 바와 같이, 이 용어는 데이터 객체의 바이트가 메모리에 저장되는 순서를 지정합니다. 프로세서는 리틀 엔디안 또는 빅 엔디안일 수 있습니다. 빅 엔디안 프로세서를 사용하면 최상위 비트를 포함하는 바이트가 가장 낮은 메모리 주소를 갖는 방식으로 데이터가 저장됩니다. 리틀 엔디안 시스템에서는 최하위 비트를 포함하는 바이트가 먼저 저장됩니다.
그림 3에 표시된 예는 0x01020304 시퀀스의 리틀 엔디안 및 빅 엔디안 스토리지를 보여줍니다.
다음 코드를 사용하여 이전 섹션의 합집합을 실험해 보겠습니다.
#include <stdio.h>#include <stdint.h>int main(){ union { struct{ uint8_t byte1; uint8_t 바이트2; }; uint16_t 단어; } u1; u1.byte1 =0x21;u1.byte2 =0x43; printf("단어:%#X", u1.word);반환 0;} 이 코드를 실행하면 다음과 같은 결과가 나타납니다.
단어:0X4321
이것은 공유 메모리 공간의 첫 번째 바이트("u1.byte1")가 "word" 변수의 최하위 바이트(0X21)를 저장하는 데 사용됨을 보여줍니다. 즉, 내가 코드를 실행하는 데 사용하는 프로세서는 리틀 엔디안입니다.
보시다시피, 이 특정 공용체 응용 프로그램은 구현 종속적 동작을 나타낼 수 있습니다. 그러나 이러한 저수준 코딩의 경우 일반적으로 프로세서의 엔디안을 알고 있기 때문에 심각한 문제는 아닙니다. 이러한 세부 사항을 모르는 경우 위의 코드를 사용하여 메모리에서 데이터가 구성되는 방식을 찾을 수 있습니다.
공용체를 사용하는 대신 비트 연산자를 사용하여 데이터 압축 또는 압축 풀기를 수행할 수도 있습니다. 예를 들어, 다음 코드를 사용하여 두 개의 1바이트 변수 "byte3" 및 "byte4"를 결합하고 단일 2바이트 변수("word2")를 생성할 수 있습니다.
<사전><코드>단어2 =(((uint16_t) 바이트3) <<8 ) | ((uint16_t) byte4);리틀 엔디안과 빅 엔디안의 경우 이 두 솔루션의 출력을 비교해 보겠습니다. 아래 코드를 고려하십시오.
#include <stdio.h>#include <stdint.h>int main(){union { struct { uint8_t byte1; uint8_t 바이트2; }; uint16_t 단어1; } u1; u1.byte1 =0x21;u1.byte2 =0x43;printf("단어1은 %#X\n", u1.단어1); uint8_t byte3, byte4;uint16_t word2;byte3 =0x21;byte4 =0x43;word2 =(((uint16_t) byte3) <<8 ) | ((uint16_t) byte4);printf("Word2는:%#X \n", word2); 반환 0;} TMS470MF03107과 같은 빅 엔디안 프로세서용으로 이 코드를 컴파일하면 , 출력은 다음과 같습니다.
Word1:0X2143
Word2는 0X2143입니다.
그러나 STM32F407IE와 같은 리틀 엔디안 프로세서용으로 컴파일하면 , 출력은 다음과 같습니다.
Word1:0X4321
Word2는 0X2143입니다.
Union 기반 방법은 하드웨어 종속 동작을 나타내는 반면 시프트 연산 기반 방법은 프로세서 엔디안과 관계없이 동일한 결과를 초래합니다. 이는 후자의 접근 방식에서 변수 이름("word2")에 값을 할당하고 컴파일러가 장치에서 사용하는 메모리 구성을 처리한다는 사실 때문입니다. 그러나 Union 기반 방법에서는 "word1" 변수를 구성하는 바이트 값을 변경합니다.
Union 기반 방법은 하드웨어 종속적 동작을 나타내지만 더 읽기 쉽고 유지 관리하기 쉽다는 이점이 있습니다. 이것이 많은 프로그래머가 이 애플리케이션에 공용체를 사용하는 것을 선호하는 이유입니다.
일반적인 직렬 통신 프로토콜로 작업할 때 데이터 패킹 또는 언패킹을 수행해야 할 수 있습니다. 각 통신 시퀀스 동안 1바이트의 데이터를 송수신하는 직렬 통신 프로토콜을 고려하십시오. 1바이트 길이의 변수로 작업하는 한 데이터 전송은 쉽지만 통신 링크를 통과해야 하는 임의의 크기의 구조가 있으면 어떻게 될까요? 이 경우 데이터 개체를 1바이트 길이 변수의 배열로 나타내야 합니다. 이 바이트 배열 표현을 얻으면 통신 링크를 통해 바이트를 전송할 수 있습니다. 그런 다음 수신기 측에서 적절하게 포장하고 원래 구조를 다시 빌드할 수 있습니다.
예를 들어 UART 통신을 통해 float 변수 "f1"을 보내야 한다고 가정합니다. float 변수는 일반적으로 4바이트를 차지합니다. 따라서 "f1"의 4바이트를 추출하기 위한 버퍼로 다음 공용체를 사용할 수 있습니다.
union { float f; 구조체 { uint8_t 바이트[4]; };} u1; 송신기는 변수 "f1"을 공용체의 float 멤버에 씁니다. 그런 다음 "바이트" 배열을 읽고 바이트를 통신 링크로 보냅니다. 리시버는 반대 작업을 수행합니다. 수신된 데이터를 자체 유니온의 "바이트" 배열에 쓰고 유니온의 부동 변수를 수신된 값으로 읽습니다. 임의의 크기의 데이터 개체를 전송하기 위해 이 기술을 수행할 수 있습니다. 다음 코드는 이 기술을 검증하기 위한 간단한 테스트가 될 수 있습니다.
#include <stdio.h>#include <stdint.h>int main(){float f1=5.5; 유니온 버퍼 { float f; 구조체 { uint8_t 바이트[4]; }; }; 통합 버퍼 버프_Tx; 통합 버퍼 buff_Rx;buff_Tx.f =f1;buff_Rx.byte[0] =buff_Tx.byte[0];buff_Rx.byte[1] =buff_Tx.byte[1];buff_Rx.byte[2] =buff_Tx .byte[2];buff_Rx.byte[3] =buff_Tx.byte[3]; printf("수신 데이터:%f", buff_Rx.f); 반환 0;} 아래 그림 4는 논의된 기술을 시각화한 것입니다. 바이트는 순차적으로 전송됩니다.
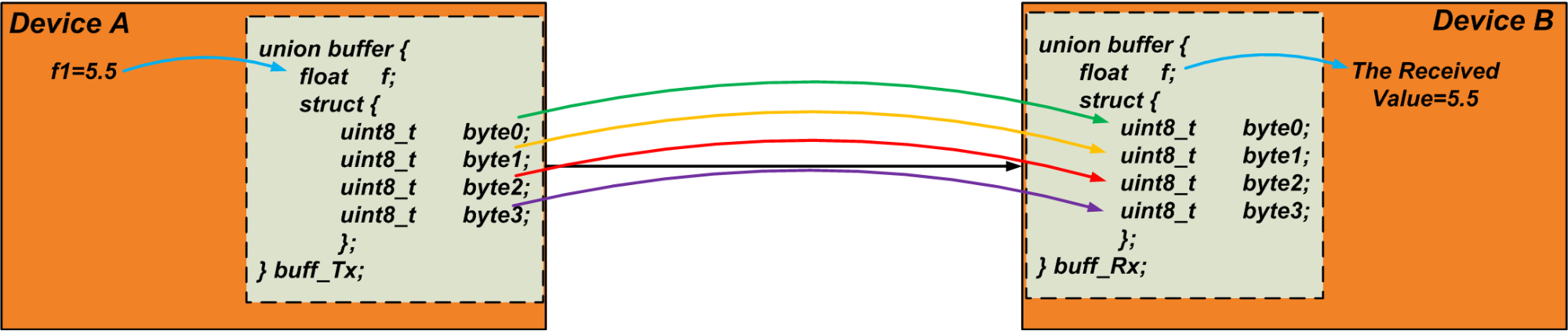
공용체의 원래 응용 프로그램은 상호 배타적인 변수에 대한 공유 메모리 영역을 만드는 것이지만 시간이 지남에 따라 프로그래머는 데이터 패킹/풀기에 공용체를 사용하는 완전히 다른 응용 프로그램에 대해 공용체를 널리 사용했습니다. 이 특별한 조합의 적용에는 조합의 한 구성원에게 값을 쓰고 다른 구성원을 읽는 것이 포함됩니다.
"Data punning" 또는 데이터 패킹/언패킹을 위해 공용체를 사용하면 하드웨어 종속 동작이 발생할 수 있습니다. 그러나 더 읽기 쉽고 유지 관리가 용이하다는 장점이 있습니다. 이것이 많은 프로그래머가 이 애플리케이션에 공용체를 사용하는 것을 선호하는 이유입니다. "Data punning"은 직렬 통신 링크를 통과해야 하는 임의 크기의 데이터 개체가 있는 경우 특히 유용할 수 있습니다.
내 기사의 전체 목록을 보려면 이 페이지를 방문하십시오.
임베디드
30년 이상 동안 Camcode의 내구성 있는 자산 레이블 솔루션을 신뢰하여 자산을 식별, 추적 및 제어할 수 있습니다. 오늘날 Camcode는 검증된 AIDC(자동 식별 및 데이터 캡처) 프로세스와 내구성 있는 자산 레이블 및 태그를 사용하여 자산을 완전히 제어하고 시스템 내에서 책임을 높이는 데도 도움이 됩니다. Camcode의 프로젝트 관리 팀은 자산에 대한 확신을 얻는 데 도움이 되는 맞춤형 서비스 및 프로세스 기반 방법을 개발하기 위해 귀하와 협력합니다. 데이터. 높은 수준의 정책 구현에서 자산 레이블 설치 및 자산 데이터
AIDC(자동 식별 및 데이터 캡처)는 키보드를 사용하지 않고 식별 및/또는 데이터를 컴퓨터 시스템 또는 휴대용 장치로 직접 수집하는 것을 설명합니다. 제조업체, 창고 관리자, 유통 센터 관리자 및 기타 업계 전문가는 품목, 재고, 도구, 자산 및 때때로 사람을 식별하고 추적하는 수단으로 AIDC를 사용합니다. 더 중요한 것은 AIDC는 데이터 입력 비용을 줄이고 식별 및/또는 데이터 수집과 관련된 오류를 제거하며 추적 데이터를 수집하여 정확한 위치를 결정하는 데 도움이 된다는 것입니다.모든 산업 프로세스와 마찬가지로 AIDC는 자