

장비 유지 보수 및 수리

산업 제조

점점 더 제조 및 기타 산업 활동을 담당하는 관리자와 엔지니어가 전략적 및 전술적 계획과 계획에 신뢰성에 중점을 두고 있습니다. 이러한 추세는 기계/시스템 설계 및 조달, 공장 운영 및 공장 유지보수를 포함한 다양한 기능 영역에 영향을 미치고 있습니다.
항공 산업에서 시작된 신뢰성 엔지니어링은 한 분야로서 역사적으로 주로 제품 신뢰성을 보장하는 데 중점을 두었습니다. 이러한 방법은 제조 공장 및 장비의 생산 신뢰성을 보장하기 위해 점점 더 많이 사용되며, 종종 린 제조를 가능하게 합니다. 이 문서에서는 다음을 포함하여 플랜트 신뢰성 엔지니어링을 위한 이러한 방법 중 가장 관련성이 높고 실용적인 소개를 제공합니다.
<울>신뢰성 공학 분야의 기원, 최소한 이에 대한 수요는 인간이 생계를 기계에 의존하기 시작한 시점으로 거슬러 올라갈 수 있습니다. 예를 들어 Noria는 세계 최초의 정교한 기계로 여겨지는 고대 펌프입니다. 강이나 개울의 흐름에서 나오는 수력 에너지를 활용하여 Noria는 양동이를 사용하여 물을 구유, 육교 및 기타 분배 장치로 이동하여 들판에 관개하고 지역 사회에 물을 제공했습니다.
Noria 공동체가 실패하면 식량 공급을 위해 거기에 의존하는 사람들이 위험에 처했습니다. 생존은 항상 신뢰성과 신뢰성에 대한 훌륭한 동기 부여의 원천이었습니다.
수요의 기원은 고대이지만 기술 분야로서의 신뢰성 공학은 제2차 세계 대전 이후 상업 항공의 성장과 함께 진정으로 번성했습니다. 추락 사고가 비즈니스에 좋지 않다는 것은 항공 산업 회사의 관리자에게 빠르게 명백해졌습니다. Karen Bernowski, Quality Progress 편집자 , MIT 통계학 교수인 Arnold Barnett가 수행하고 1994년에 보고한 다양한 수단에 의한 죽음의 미디어 가치에 대한 그녀의 사설 연구 중 하나에서 밝혔습니다.
Barnett은 다양한 방법으로 1,000명의 사망자당 New York Times의 1면 뉴스 기사 수를 평가했습니다. 그는 암 관련 사망이 1,000명당 0.02개의 1면 뉴스 기사를 산출하고, 1,000명당 살인이 1.7개, AIDS로 인한 사망 1,000명당 2.3개, 항공 관련 사고가 1,000명당 무려 138.2개의 기사를 산출한다는 것을 발견했습니다!
항공 관련 사고의 비용과 세간의 이목을 끄는 특성은 항공 산업이 신뢰성 공학 분야의 개발에 크게 참여하도록 동기를 부여하는 데 도움이 되었습니다. 마찬가지로, 국방에서 군사 장비의 중요한 특성으로 인해 신뢰성 엔지니어링 기술은 작전 준비 상태를 보장하기 위해 오랫동안 사용되어 왔습니다. 신뢰성 엔지니어링 분야의 많은 표준은 MIL 표준이거나 군사 활동에서 유래했습니다.
신뢰성 엔지니어링은 부품, 제품 및 시스템의 수명과 신뢰성을 다룹니다. 더 신랄하게, 그것은 위험을 통제하는 것에 관한 것입니다. 신뢰성 엔지니어링은 엔지니어가 이러한 부품, 제품 및 시스템의 고장 모드와 패턴을 이해하는 데 도움이 되도록 설계된 다양한 분석 기술을 통합합니다. 전통적으로 신뢰성 엔지니어링 분야는 제품 신뢰성과 신뢰성 보증에 중점을 두었습니다.
최근 몇 년 동안 생산 환경에서 기계 및 기타 물리적 자산을 배포하는 조직은 생산 안정성 및 신뢰성 보장을 위해 다양한 안정성 엔지니어링 원칙을 배포하기 시작했습니다.
점점 더 많은 생산 조직에서 고장 모드 및 영향(및 중요도) 분석(FMEA, FMECA), 근본 원인 분석(RCA), 상태 기반 유지 관리, 개선된 작업 계획 계획, 등. 이러한 조직은 낮은 신뢰성의 근본 원인을 제어하기 위해 수명 주기 비용 기반 설계 및 조달 전략, 변경 관리 계획 및 기타 고급 도구 및 기술을 채택하기 시작했습니다.
그러나 생산 신뢰성 보증 커뮤니티에서 신뢰성 엔지니어링의 보다 정량적인 측면을 채택하는 것은 더뎠습니다. 이는 부분적으로는 기술의 복잡성으로 인식되고 부분적으로는 유용한 데이터를 얻는 데 어려움이 있기 때문입니다.
신뢰성 엔지니어링의 양적 측면은 표면적으로는 복잡하고 벅차게 보일 수 있습니다. 그러나 실제로 가장 기본적이고 광범위하게 적용할 수 있는 방법에 대한 비교적 기본적인 이해를 통해 플랜트 신뢰성 엔지니어는 문제가 발생하는 위치, 문제의 특성 및 생산 프로세스에 대한 영향에 대해 적어도 양적으로 훨씬 더 명확하게 이해할 수 있습니다. 센스.
정량적 신뢰성 엔지니어링 도구와 방법을 적절하게 사용하면 플랜트 신뢰성 엔지니어링이 RCM, RCA 등이 제공하는 프레임워크를 보다 효과적으로 적용할 수 있습니다. 그러나 엔지니어는 방법을 적용하는 데 특히 영리해야 합니다.
왜요? 생산 프로세스의 운영 컨텍스트와 환경은 제품 신뢰성 보증의 다소 1차원적인 세계보다 더 많은 변수를 통합합니다. 이는 설계 엔지니어링, 조달, 생산/운영, 유지보수 등의 복합적인 영향과 일반적인 생산 환경의 다차원적 측면을 모델링하기 위한 효과적인 테스트 및 실험을 생성하기가 어렵기 때문입니다.
생산 환경에서 정량적 신뢰성 방법을 적용하는 데 어려움이 증가함에도 불구하고 도구를 제대로 이해하고 적절한 곳에 적용하는 것은 가치가 있습니다. 정량적 데이터는 문제/기회의 성격과 규모를 정의하는 데 도움이 되며, 이는 다른 신뢰성 엔지니어링 도구를 적용할 때 신뢰성에 대한 비전을 제공합니다.
이 기사에서는 생산 신뢰성 보증에 관심이 있는 플랜트 엔지니어에게 적용할 수 있는 가장 기본적인 신뢰성 엔지니어링 방법을 소개합니다. 가우스(정규) 분포(예:중심 경향 측정, 분산 및 변동 측정, 신뢰 구간 등)에 기반한 대수, 확률 이론 및 일변량 통계에 대한 기본 이해를 전제로 합니다.
이 문서는 신뢰성 방법에 대한 간략한 소개라는 점을 분명히 해야 합니다. 이것은 신뢰성 엔지니어링 방법에 대한 포괄적인 조사가 아니며 어떤 식으로든 새롭거나 관습에 얽매이지 않습니다. 여기에 설명된 방법은 신뢰성 엔지니어가 일상적으로 사용하며 ASQ(American Society for Quality)에서 CRE(신뢰성 엔지니어)로서 전문 인증을 추구하는 사람들을 위한 핵심 지식 개념입니다.
신뢰성 엔지니어링에 관한 여러 책이 이 기사의 참고 문헌에 나열되어 있습니다. 이 기사의 저자는 엔지니어를 위한 신뢰성 방법을 찾았습니다. by K.S. Krishnamorthi 및 신뢰성 통계 신뢰성 엔지니어링 방법에 관한 특히 유용하고 사용자 친화적인 참고 자료로 Robert Dovich가 작성했습니다. 둘 다 ASQ Press에서 발행합니다.
방법을 논의하기 전에 신뢰성 엔지니어링 명명법을 숙지해야 합니다. 편의를 위해 이 기사의 부록에 주요 용어 및 정의의 간략한 목록이 제공됩니다. 신뢰성 용어 및 명명법에 대한 보다 철저한 정의는 MIL-STD-721 및 기타 관련 표준을 참조하십시오. 부록에 포함된 정의는 MIL-STD-721에서 가져온 것입니다.
많은 수학적 개념이 특히 확률 및 통계 영역에서 신뢰성 엔지니어링에 적용됩니다. 마찬가지로, 가우스(정규) 분포, 로그 정규 분포, Rayleigh 분포, 지수 분포, Weibull 분포 및 기타 호스트를 포함하여 많은 수학적 분포를 다양한 목적으로 사용할 수 있습니다.
이 간략한 소개의 목적을 위해 우리는 신뢰도 엔지니어링에 가장 널리 적용되는 지수 분포와 Weibull 분포로 논의를 제한할 것입니다. 간결함과 단순함을 위해 분포 적합도 및 신뢰 구간과 같은 중요한 수학적 개념은 제외되었습니다.
정량적 신뢰도 측정의 목적은 시간에 대한 고장률을 정의하고 고장의 양적 측면을 이해하기 위해 수학적 분포에서 고장률을 모델링하는 것입니다. 가장 기본적인 구성 요소는 다음 방정식을 사용하여 추정되는 고장률입니다.

여기서:
λ =고장률(때로는 위험률이라고도 함)
T =총 실행 시간/사이클/마일/기타. 실패한 항목과 실패하지 않은 항목 모두에 대한 조사 기간 동안.
r =조사 기간 동안 발생한 총 고장 횟수입니다.
예를 들어, 5개의 전기 모터가 총 50년 동안 작동하고 해당 기간 동안 5개의 기능 고장이 있는 경우 고장률은 연간 0.1개의 고장입니다.
또 다른 매우 기본적인 개념은 MTBF/MTTF(mean time between failure)입니다. MTBF와 MTTF의 유일한 차이점은 고장 시 수리되는 항목을 언급할 때 MTBF를 사용한다는 것입니다. 단순히 버리고 교체되는 품목의 경우 MTTF라는 용어를 사용합니다. 계산은 동일합니다.
중심 경향의 측정값인 MTBF(평균 고장 시간)와 MTTF(평균 고장 시간)를 추정하는 기본 계산은 단순히 고장률 함수의 역수입니다. 다음 방정식을 사용하여 계산됩니다.

여기서:
θ =실패 사이/고장까지의 평균 시간
T =총 실행 시간/사이클/마일/기타. 실패한 항목과 실패하지 않은 항목 모두에 대한 조사 기간 동안.
r =조사 기간 동안 발생한 총 고장 횟수입니다.
산업용 전기 모터의 예에 대한 MTBF는 10년이며, 이는 모터의 고장률의 역수입니다. 덧붙여서, 우리는 고장 시 재구축되는 전기 모터에 대한 MTBF를 추정할 것입니다. 일회용으로 간주되는 더 작은 모터의 경우 중심 경향 측정을 MTTF로 명시합니다.
고장률은 훨씬 더 복잡한 신뢰도 계산의 기본 구성요소입니다. 기계/전기 설계, 작동 상황, 환경 및/또는 유지보수 효율성에 따라 시간의 함수로서의 기계의 고장률은 감소하거나 일정하게 유지되거나 선형적으로 증가하거나 기하학적으로 증가할 수 있습니다(그림 1). 실패율 대 시간의 중요성은 나중에 더 자세히 논의될 것입니다.
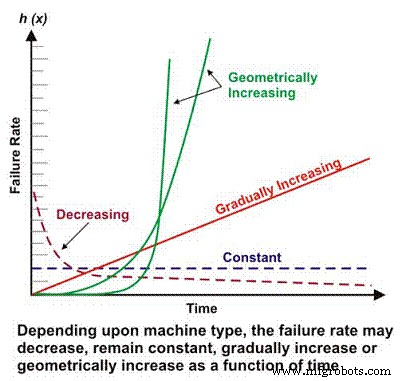
그림 1. 다양한 실패율 대 시간 시나리오
확률과 통계에 대한 기본 교육만 받은 개인은 친숙한 종 모양의 확률 밀도 곡선과 관련된 가우스 또는 정규 분포에 가장 익숙할 것입니다. 가우스 분포는 일반적으로 중심 경향의 두 가지 가장 일반적인 측정값인 평균과 중앙값이 거의 동일한 데이터 세트에 적용할 수 있습니다.
놀랍게도, 표준화된 테스트 점수에서 아기의 출생 체중에 이르는 현상에 대한 확률을 모델링하는 가우스 분포의 다양성에도 불구하고 신뢰도 공학에서 사용되는 지배적인 분포는 아닙니다. 가우스 분포는 주요 고장 모드가 있는 기계의 고장 특성을 평가하는 데 사용되지만 신뢰성 엔지니어링에 사용되는 주요 분포는 지수 분포입니다.
기계의 신뢰성과 고장 특성을 평가할 때 고장률 대 시간을 반영하는 많이 악의적인 "욕조" 곡선부터 시작해야 합니다(그림 2). 개념적으로 욕조 곡선은 기계의 세 가지 기본 고장률 특성인 감소, 일정 또는 증가를 효과적으로 보여줍니다. 유감스럽게도 욕조 곡선은 거시적 수준에서 일반적으로 나타나는 산업 플랜트의 대부분의 기계에 대한 특성 고장률을 효과적으로 모델링하지 못하기 때문에 유지 보수 엔지니어링 문헌에서 심한 비판을 받았습니다.
대부분의 기계는 초기 수명 또는 영아 사망률 및/또는 욕조 곡선의 일정한 고장률 영역에서 수명을 보냅니다. 산업 기계에서 체계적인 시간 기반 오류는 거의 볼 수 없습니다. 일반적인 산업 기계의 고장률을 모델링하는 데에는 한계가 있지만 욕조 곡선은 신뢰성 공학의 기본 개념을 설명하는 데 유용한 도구입니다.
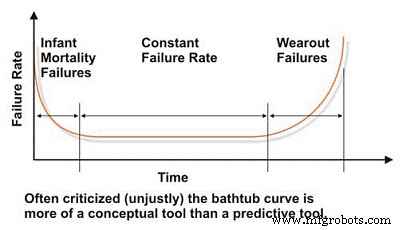
그림 2. 악의적인 '욕조' 곡선
인체는 욕조 곡선을 따르는 시스템의 좋은 예입니다. 사람과 그 문제에 대한 기타 유기종은 생후 첫 해, 특히 첫 몇 년 동안 높은 실패율(사망률)을 겪는 경향이 있지만, 아이가 자라면서 그 비율은 감소합니다. 사람이 사춘기에 도달하고 10대를 살아남는다고 가정하면 사망률은 상당히 일정해지고 연령(시간) 의존성 질병이 사망률(소진)을 증가시키기 시작할 때까지 그 상태를 유지합니다.
산전 관리와 산모의 영양, 의료의 질과 이용 가능성, 환경과 영양, 생활 방식 선택, 그리고 물론 유전적 소인을 비롯한 수많은 영향이 사망률에 영향을 미칩니다. 이러한 요소는 기계 수명에 영향을 미치는 요소를 은유적으로 비교할 수 있습니다. 디자인과 조달은 유전적 소인과 유사합니다. 설치 및 시운전은 산전 관리 및 산모의 영양과 유사합니다. 생활 방식 선택 및 의료 서비스 이용 가능성은 유지 관리 효율성 및 운영 조건에 대한 사전 통제와 유사합니다.
가장 기본적이고 널리 사용되는 신뢰도 예측 공식인 지수 분포는 일정한 고장률 또는 욕조 곡선의 평평한 부분을 가진 기계를 모델링합니다. 대부분의 산업용 기계는 수명의 대부분을 일정한 고장률로 보내므로 널리 적용할 수 있습니다. 다음은 지수 분포를 따르는 기계의 신뢰성을 추정하기 위한 기본 방정식으로, 여기서 고장률은 시간의 함수로 일정합니다.

여기서:
R(t) =일정 기간, 주기, 마일 등의 신뢰도 추정치(t).
e =자연 로그의 밑(2.718281828)
λ =실패율(1/MTBF 또는 1/MTTF)
전기 모터의 예에서 고장률이 일정하다고 가정하면 모터가 고장 없이 6년 동안 작동할 가능성 또는 예상 신뢰도는 55%입니다. 이것은 다음과 같이 계산됩니다.
R(6) =2.718281828-(0.1* 6)
R(6) =0.5488 =~ 55%
다시 말해, 6년 후에 동일한 애플리케이션에서 작동하는 동일한 모터 인구의 약 45%가 확률적으로 실패할 것으로 예상할 수 있습니다. 이 계산이 모집단의 확률을 예측한다는 점을 이 시점에서 반복할 가치가 있습니다. 인구 중 주어진 개인은 수술 첫날에 실패할 수 있고 다른 개인은 30년 동안 지속될 수 있습니다. 이것이 확률론적 신뢰도 예측의 특성입니다.
지수분포의 특징은 MTBF가 계산된 신뢰도가 36.78%인 지점 또는 이미 63.22%의 기계가 고장난 지점에서 발생한다는 것이다. 우리의 모터 예에서 10년 후 동일한 애플리케이션에서 작동하는 동일한 모터 모집단의 모터 중 63.22%가 고장날 것으로 예상할 수 있습니다. 즉, 생존율은 인구의 36.78%입니다.
우리는 종종 예상 베어링 수명을 L10 수명이라고 합니다. 이것은 베어링 모집단의 10%가 고장날 것으로 예상되는 시점입니다(90% 생존율). 실제로 베어링의 일부만 실제로 L10 지점까지 생존합니다. 우리는 베어링이 평균적으로 예상 MTBF까지 지속되고 있음을 나타내는 L63.22 지점에 초점을 맞춰야 할 때 베어링의 객관적인 수명으로 이를 받아들이게 되었습니다. 물론 베어링이 다음과 같다고 가정하면 지수 분포를 따릅니다. 이 문제는 나중에 기사의 Weibull 분석 섹션에서 논의할 것입니다.
확률 밀도 함수(pdf) 또는 수명 분포는 고장 빈도 분포를 근사화하는 수학 방정식입니다. 가우스 또는 정규 분포에서 익숙한 종 모양의 곡선을 생성하는 것은 pdf 또는 수명 빈도 분포입니다. 아래는 지수 분포에 대한 pdf입니다.

여기서:
pdf(t) =주어진 시간 동안의 수명 빈도 분포(t)
e =자연 로그의 밑(2.718281828)
λ =실패율(1/MTBF 또는 1/MTTF)
전기 모터의 예에서 3년 후의 실제 고장 가능성은 다음과 같이 계산됩니다.
pdf(3) =01. * 2.718281828-(0.1* 3)
pdf(3) =0.1 * 0.7408
pdf(3) =.07408 =~ 7.4%
이 예에서 지수 분포를 따르는 일정한 고장률을 가정하면 산업용 전기 모터의 수명 분포 또는 pdf가 그림 3에 표시됩니다. pdf 함수의 감소 특성으로 인해 혼동하지 마십시오. 예, 고장률은 일정하지만 pdf는 교체 없이 고장이 난다고 수학적으로 가정하므로 고장이 발생할 수 있는 모집단이 지속적으로 감소하여 점근적으로 0에 접근합니다.
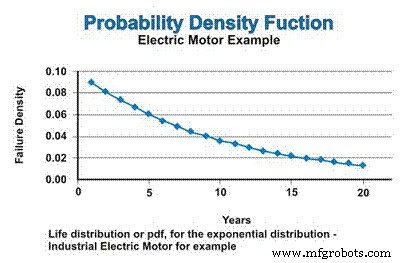
그림 3. 확률 밀도 함수(pdf)
누적 분포 함수(cdf)는 단순히 일정 기간 동안 예상할 수 있는 누적 실패 횟수입니다. 지수 분포의 경우 고장률이 일정하므로 고장난 구성 요소가 cdf에 추가되는 상대 비율은 일정하게 유지됩니다. 그러나 고장의 결과로 인구가 감소함에 따라 수학적으로 추정된 실제 고장 수는 감소하는 인구의 함수로 감소합니다. pdf가 0에 점근적으로 접근하는 것과 마찬가지로 cdf는 1에 점근적으로 접근합니다(그림 4).
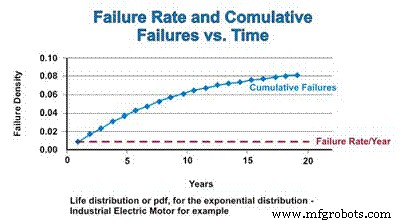
그림 4. 실패율과 누적 분포 함수
종종 유아 사망률 영역이라고 하는 욕조 곡선의 감소하는 고장률 부분과 마모 영역은 다용도 Weibull 분포를 다루는 다음 섹션에서 논의될 것입니다.
Weibull 배포
원래 스웨덴 수학자 Wallodi Weibull이 개발한 Weibull 분석은 신뢰성 엔지니어가 사용하는 가장 다재다능한 분포입니다. 분포라고 하지만 실제로는 신뢰성 엔지니어가 고장 데이터 세트의 확률 밀도 함수(고장 빈도 분포)를 먼저 특성화하여 고장을 초기 수명, 상수(지수) 또는 마모로 특성화할 수 있도록 하는 도구입니다. (가우스 또는 로그 법선) 고장까지의 시간/주기/마일의 로그를 사용하여 특수 플로팅 용지에 고장까지의 시간 데이터를 플로팅하여 로그에 각 고장으로 표시되는 모집단의 누적 백분율에 대한 로그 스케일 X축을 플로팅함 -log 스케일 Y축(그림 5).
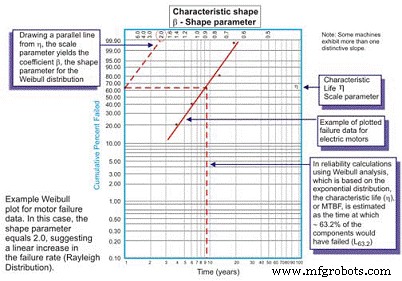
그림 5. 간단한 Weibull 도표 – 주석
일단 플로팅되면 결과 곡선의 선형 기울기는 â로 표시되는 형상 매개변수라고 하는 중요한 변수이며, 다양한 실패 분포에 맞게 지수 분포를 조정하는 데 사용됩니다. 일반적으로 â 계수 또는 모양 매개변수가 1.0보다 작으면 분포가 초기 수명 또는 영아 사망률 실패를 나타냅니다. 형상 매개변수가 약 3.5를 초과하면 데이터는 시간에 따라 달라지며 마모 실패를 나타냅니다.
이 데이터 세트는 일반적으로 가우스 또는 정규 분포를 가정합니다. â 계수가 ~ 3.5 이상으로 증가하면 종 모양의 분포가 조여져 첨도(곡선 상단의 정점)가 증가하고 표준 편차가 작아집니다. 많은 데이터 세트는 2개 또는 3개의 별개 영역을 나타냅니다.
예를 들어, 신뢰성 엔지니어는 실행 중 형상 매개변수를 나타내는 하나의 곡선과 일정하거나 점진적으로 증가하는 고장률을 나타내는 다른 곡선을 그리는 것이 일반적입니다. 어떤 경우에는 마모 영역인 세 번째 모양을 식별하기 위해 세 번째 뚜렷한 선형 기울기가 나타납니다.
이러한 경우 고장 데이터의 pdf는 실제로 친숙한 욕조 곡선 모양을 가정합니다(그림 6). 그러나 공장에서 사용되는 대부분의 기계 장비는 영아 사망률 영역과 일정하거나 점진적으로 증가하는 고장률 영역을 나타냅니다. 마모를 나타내는 곡선이 나타나는 경우는 드뭅니다. 특성 수명 또는 η(소문자 그리스어 "Eta")는 MTBF의 Weibull 근사치입니다. 지수 분포에 대한 MTBF/MTTF인 평가 중인 장치의 63.21%가 실패한 것은 항상 시간, 마일 또는 주기의 함수입니다.
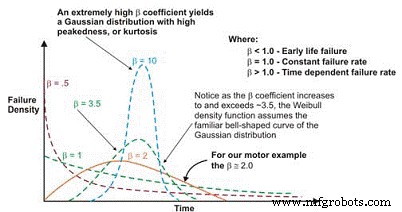
그림 6. 형상 매개변수에 따른 Weibull 파손 밀도 곡선은 여러 분포를 가정할 수 있으므로 안정성 엔지니어링에 매우 다양합니다.
이 도구를 유지 관리 및 운영 우수성과 다시 연결하기 위한 주의 사항으로 윤활, 오염 제어, 정렬, 균형, 베어링, 기어 등의 기계적 고장으로 이어지는 강제 기능을 보다 효과적으로 제어하려면 적절한 작동 등을 통해 더 많은 기계가 실제로 피로 수명에 도달할 것입니다. 피로 수명에 도달한 기계는 친숙한 마모 특성을 나타냅니다.
β 계수를 사용하여 고장률 방정식을 시간의 함수로 조정하면 다음과 같은 일반 방정식이 생성됩니다.

위치:
h(t) =주어진 시간(t) 동안의 고장률(또는 위험률)
e =자연 로그의 밑(2.718281828)
θ =추정된 MTBF/MTTF
β =플롯의 Weibull 형상 매개변수
그리고, 다음과 같은 신뢰성 기능:
위치:
R(t) =시간, 주기, 마일 등의 기간에 대한 신뢰도 추정치. (t)
e =자연 로그의 밑(2.718281828)
θ =추정된 MTBF/MTTF
β =플롯의 Weibull 형상 매개변수
그리고, 다음 확률 밀도 함수(pdf):
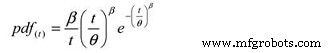
위치:
pdf(t) =일정 기간,
주기, 마일 등의 확률 밀도 함수 추정값. (t)
e =자연 로그의 밑(2.718281828)
θ =추정된 MTBF/MTTF
β =플롯의 Weibull 형상 매개변수
β가 1.0일 때 Weibull 분포는 기반이 되는 지수 분포의 형태를 취합니다.
초심자에게는 Weibull 분석을 수행하는 데 필요한 수학이 어려워 보일 수 있습니다. 그러나 공식의 역학을 이해하면 수학은 정말 간단합니다. 또한 오늘날 대부분의 작업은 소프트웨어가 대신하지만 플랜트 신뢰성 엔지니어가 강력한 Weibull 분석 기술을 효과적으로 배포할 수 있도록 기본 이론을 이해하는 것이 중요합니다.
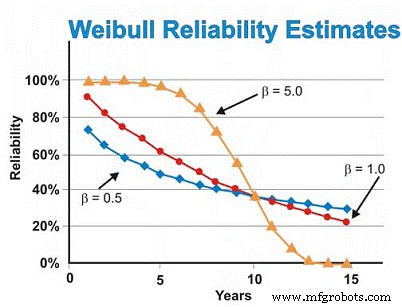
이전에 논의된 전기 모터의 예에서 우리는 이전에 지수 분포를 가정했습니다. 그러나 Weibull 분석이 0.5의 β 형상 매개변수를 산출하여 초기 수명 고장을 밝혀낸 경우 6년 후의 신뢰도 추정치는 지수 분포를 가정하여 추정된 ~55%가 아니라 ~46%가 됩니다. 마모 실패를 줄이려면 더 잘 제작되고 전달된 품질과 신뢰성을 제공하고 녹, 부식, 마모 및 기타 정적 마모 메커니즘을 방지하기 위해 모터를 더 잘 보관하고 설치 작업을 더 잘 수행하기 위해 공급업체에 의존해야 합니다. 새 기계 또는 재건된 기계를 시작합니다.
반대로, Weibull 분석이 모터가 5.0의 β 형상 매개변수를 산출하는 주로 마모 관련 고장을 나타내는 것으로 밝혀지면 지수 분포를 가정하여 추정된 ~55% 대신 6년 동안의 신뢰도 추정치는 ~93%가 될 것입니다. 시간 종속적 마모 실패의 경우 마모 영역에 도달한 후 MTBF/MTTF에 대한 좋은 추정치가 있고 표준 편차가 충분히 작다고 가정하여 예정된 정밀 검사 또는 교체를 수행하여 다음과 같은 높은 신뢰도의 재구축/교체 결정을 내릴 수 있습니다. 비용이 많이 들지 않습니다.
모터 예에서 β 형상 매개변수가 5.0이라고 가정하면 약 5~6년 후에 고장률이 급격히 증가하기 시작하므로 시간 기반 교체 또는 재건을 추정할 때 마모 영역에만 초점을 맞추도록 데이터를 편집할 수 있습니다. 시각. 또는 "응력-강도" 간섭을 줄이기 위해 지배적인 고장 모드를 목표로 설계를 개선할 수 있습니다. 즉, 설계 수정을 통해 기계의 결함을 제거하려고 시도할 수 있으며 목표는 시간 종속적 오류를 일으키는 원인을 제거하는 것입니다.
β 형상 매개변수를 제외하고 모든 것이 일정하다고 가정하면 그림 7은 β 형상 값이 0.5(초기 수명), 1.0(상수 또는 지수) 및 5.0(마모)이라고 가정할 때 신뢰도 추정치에 대한 β 형상 매개변수의 차이를 보여줍니다. 시간 추정 범위. 이 그래픽은 시간 대비 위험 증가(β =0.5), 시간 대비 일정 위험(β =1.0) 및 시간 대비 위험 증가(β =5)의 개념을 시각적으로 보여줍니다.
그림 7. 시간에 따른 다양한 신뢰성 예측 Weibull 모양 매개변수
종종 Weibull 플롯의 데이터 포인트를 통해 최적 회귀선을 그릴 때 상관 계수가 좋지 않아 실제 데이터 포인트가 회귀선에서 멀리 떨어져 있음을 의미합니다. 이것은 상관 계수 R, 더 보수적으로는 데이터 변동성을 나타내는 R2를 조사하여 평가됩니다. 상관 관계가 좋지 않으면 신뢰성 엔지니어는 데이터를 조사하여 두 개 이상의 패턴이 존재하는지 평가해야 합니다. 이는 고장 모드, 작동 컨텍스트 등의 주요 차이점을 나타낼 수 있습니다. 이는 종종 두 개 이상의 베타 추정치를 생성합니다(그림 8).
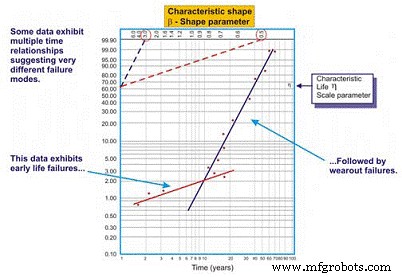
그림 8. 다중 베타 Weibull 도표의 예
그림 8의 예에서 볼 수 있듯이 두 개의 개별 회귀선을 그릴 때 데이터 세트가 더 잘 작동합니다. 첫 번째 라인은 0.5의 베타 모양 매개변수를 보여 초기 수명 실패를 나타냅니다. 두 번째 선은 3.0의 베타 모양을 나타내어 실패 위험이 시간의 함수로 증가함을 나타냅니다. 복잡한 장비, 특히 기계 장비는 새롭거나 최근에 재건할 때 "런인(run-in)" 오류가 발생하는 것이 일반적입니다. 따라서 초기 시작 직후에 실패 위험이 가장 높습니다.
시스템이 시스템 유형에 따라 몇 분, 몇 시간, 며칠, 몇 주, 몇 년 또는 몇 년이 걸릴 수 있는 실행 기간을 통해 작동하면 시스템은 다른 위험 패턴에 들어갑니다. 이 예에서 시스템은 시작 기간을 종료하면 시간의 함수로 실패 위험이 증가하는 기간에 들어갑니다.
다중 베타는 신뢰성 엔지니어에게 시간의 함수로서 위험을 보다 정확하게 추정할 수 있도록 합니다. 이 지식으로 무장하면 완화 조치를 취할 수 있는 더 나은 위치에 있습니다. 예를 들어, 초기 수명 기간 동안 우리는 제조/재구축, 설치 및 시작의 정밀도를 향상시키는 경향이 있습니다. 또한 고위험 기간 동안 모니터링 기술을 추가하거나 모니터링 빈도를 늘릴 수 있습니다. 도입 기간 후에 시스템에 영향을 미치는 것으로 생각되는 시간 종속적 마모 오류를 대상으로 하는 모니터링 기술을 도입하거나 그에 따라 모니터링 빈도를 늘리거나 경우에 따라 "어려운" 예방 유지 관리 작업을 예약할 수 있습니다.
작동 상황 및 필요한 임무 시간과 관련하여 구성 요소 또는 기계의 신뢰성이 설정되면 플랜트 엔지니어는 시스템 또는 프로세스의 신뢰성을 평가해야 합니다. 다시 말하지만, 간결함과 단순성을 위해 직렬, 병렬 및 공유 부하 중복 시스템(r/n 시스템)에 대한 시스템 안정성 추정치를 논의합니다.
시리즈 시스템
시리즈 시스템에 대해 논의하기 전에 안정성 블록 다이어그램에 대해 논의해야 합니다. 사용하기 복잡한 도구가 아니라 신뢰성 블록 다이어그램은 처음부터 끝까지 프로세스를 간단히 매핑합니다. 시리즈 시스템의 경우 하위 시스템 A 다음에 하위 시스템 B가 오는 식입니다. 직렬 시스템에서 하위 시스템 B를 사용할 수 있는 능력은 하위 시스템 A의 작동 상태에 따라 다릅니다. 하위 시스템 A가 작동하지 않으면 시스템은 하위 시스템 B의 상태에 관계없이 다운됩니다(그림 9).
To calculate the system reliability for a serial process, you only need to multiply the estimated reliability of Subsystem A at time (t) by the estimated reliability of Subsystem B at time (t). The basic equation for calculating the system reliability of a simple series system is:
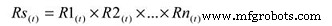
Where:
Rs(t) – System reliability for given time (t)
R1-n(t) – Subsystem or sub-function reliability for given time (t)
So, for a simple system with three subsystems, or sub-functions, each having an estimated reliability of 0.90 (90%) at time (t), the system reliability is calculated as 0.90 X 0.90 X 0.90 =0.729, or about 73%.
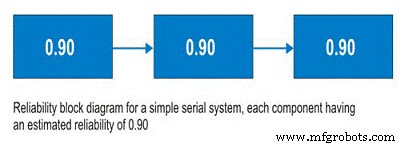
Figure 9. Simple Serial System
Parallel Systems
Often, design engineers will incorporate redundancy into critical machines. Reliability engineers call these parallel systems. These systems may be designed as active parallel systems or standby parallel systems. The block diagram for a simple two component parallel system is shown in Figure 10.
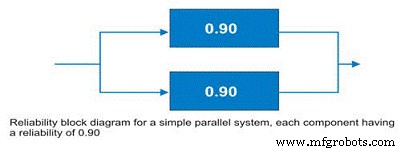
Figure 10. Simple parallel system – the system reliability is increased to 99% due to the redundancy.
To calculate the reliability of an active parallel system, where both machines are running, use the following simple equation:
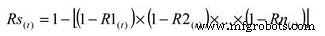
Where:
Rs(t) – System reliability for given time (t)
R1-n(t) – Subsystem or sub-function reliability for given time (t)
The simple parallel system in our example with two components in parallel, each having a reliability of 0.90, has a total system reliability of 1 – (0.1 X 0.1) =0.99. So, the system reliability was significantly improved.
There are some shortcut methods for calculating parallel system reliability when all subsystems have the same estimated reliability. More often, systems contain parallel and serial subcomponents as depicted in Figure 11. The calculation of standby systems requires knowledge about the reliability of the switching mechanism. In the interest of simplicity and brevity, this topic will be reserved for a future article.
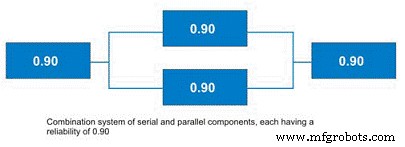
Figure 11. Combination System with Parallel and Serial Elements
r out of n Systems (r/n Systems)
An important concept to plant reliability engineers is the concept of r/n systems. These systems require that r units from a total population in n be available for use. A great industrial example is coal pulverizers in an electric power generating plant. Often, the engineers design this function in the plant using an r/n approach. For instance, a unit has four pulverizers and the unit requires that three of the four be operable to run at the unit’s full load (see Figure 12).
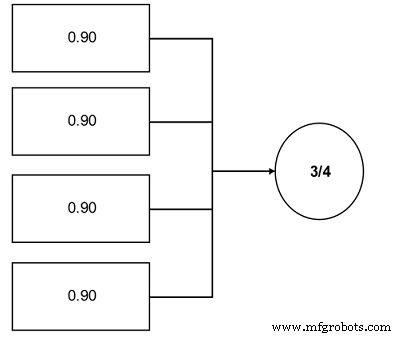
Figure 12. Simple r/n system example – Three of the four components are required.
The reliability calculation for an r/n system can be reduced to a simple cumulative binomial distribution calculation, the formula for which is:
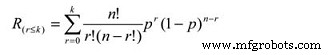
Where:
Rs =System reliability given the actual number of failures (r) is less than or equal the maximum allowable (k)
r =The actual number of failures
k =The maximum allowable number of failures
n =The total number of units in the system
p =The probability of survival, or the subcomponent reliability for a given time (t).
This equation is somewhat more complicated. In our pulverizer example, assuming a subcomponent reliability of 0.90, the equation works out as a summation of the following:
P(0) =0.6561
P(1) =0.2916
So, the likelihood of completing the mission time (t) is 0.9477 (0.6561 + 0.2916), or approximately 95%.
Field Data Collection
To employ the reliability analysis methods described herein, the engineer requires data. It is imperative to establish field data collection systems to support your reliability management initiatives. Likewise, as much as possible, you’ll want to employ common nomenclature and units so that your data can be parsed effectively for more detailed analysis. Collect the following information:
A good general system for data collection is described in the IEC standard 300-3-2. In addition to providing instructions for collecting field data, it provides a standard taxonomy of failure modes. Other taxonomies have been established, but the IEC standard represents a good starting point for your organization to define its own. Likewise, DOE standard NE-1004-92 offers a very nice standard nomenclature of failure causes.
An important benefit derived from your efforts to collect good field data is that it enables you to break the “random trap.” As I mentioned earlier, the bathtub curve has been much maligned – particularly in the Reliability-Centered Maintenance literature. While it’s true that Weibull analysis reveals that few complex mechanical systems exhibit time-dependent wearout failures, the reason, at least in part, is due to the fact that the reliability of complex systems is affected by a wide variety of failure modes and mechanisms.
When these are lumped together, there is a “randomizing” effect, which makes the failures appear to lack any time dependency. However, if the failure modes were analyzed individually, the story would likely be very different (Figure 13). For certain, some failure modes would still be mathematically random, but many, and arguably most, would exhibit a time dependency. This kind of information would arm reliability engineers and managers with a powerful set of options for mitigating failure risk with a high degree of precision. Naturally, this ability depends upon the effective collection and subsequent analysis of field data.
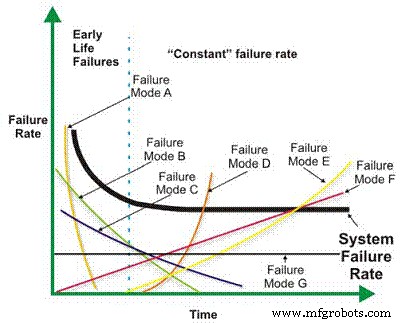
Figure 13. Good field data collection enables you to break the random trap.
This brief introduction to reliability engineering methods is intended to expose the otherwise uninitiated plant engineer to the world of quantitative reliability engineering. The subject is quite broad, however, and I’ve only touched on the major reliability methods that I believe are most applicable to the plant engineer. I encourage you to further investigate the field of reliability engineering methods, concentrating on the following topics, among others:
<울> <리>More detailed understanding of the Weibull distribution and its applications
<리>More detailed understanding of the exponential distribution and its applications
<리>The Gaussian distribution and its applications
<리>The log-normal distribution and its applications
<리>Confidence intervals (binomial, chi-square/Poisson, etc.)
<리>Beta distribution and its applications
<리>Bayesian applications of reliability engineering methods
<리>Stress-strength interference analysis
<리>Testing options and their applicability to plant reliability engineering
<리>Reliability growth strategies and management
<리>More detailed understanding of field data collection.
Most important, spend time learning how to apply reliability engineering methods to plant reliability problems. If your interest in reliability engineering methods is high, I encourage you to pursue professional certification by the American Society for Quality as a reliability engineer (CRE).
References
Troyer, D. (2006) Strategic Plant Reliability Management Course Book, Noria Publishing, Tulsa, Oklahoma.
Bernowski, K (1997) “Safety in the Skies,” Quality Progress , January.
Dovich, R. (1990) Reliability Statistics, ASQ Quality Press, Milwaukee, WI.
Krishnamoorthi, K.S. (1992) Reliability Methods for Engineers, ASQ Quality Press , Milwaukee, WI.
MIL Standard 721
IEC Standard 300-3-3
DOE Standard NE-1004-92
Appendix:Select reliability engineering terms from MIL STD 721
Availability – A measure of the degree to which an item is in the operable and committable state at the start of the mission, when the mission is called for at an unknown state.
Capability – A measure of the ability of an item to achieve mission objectives given the conditions during the mission.
Dependability – A measure of the degree to which an item is operable and capable of performing its required function at any (random) time during a specified mission profile, given the availability at the start of the mission.
Failure – The event, or inoperable state, in which an item, or part of an item, does not, or would not, perform as previously specified.
Failure, dependent – Failure which is caused by the failure of an associated item(s). Not independent.
Failure, independent – Failure which occurs without being caused by the failure of any other item. Not dependent.
Failure mechanism – The physical, chemical, electrical, thermal or other process which results in failure.
Failure mode – The consequence of the mechanism through which the failure occurs, i.e. short, open, fracture, excessive wear.
Failure, random – Failure whose occurrence is predictable only in the probabilistic or statistical sense. This applies to all distributions.
Failure rate – The total number of failures within an item population, divided by the total number of life units expended by that population, during a particular measurement interval under stated conditions.
Maintainability – The measure of the ability of an item to be retained or restored to specified condition when maintenance is performed by personnel having specified skill levels, using prescribed procedures and resources, at each prescribed level of maintenance and repair.
Maintenance, corrective – All actions performed, as a result of failure, to restore an item to a specified condition. Corrective maintenance can include any or all of the following steps:localization, isolation, disassembly, interchange, reassembly, alignment and checkout.
Maintenance, preventive – All actions performed in an attempt to retain an item in a specified condition by providing systematic inspection, detection and prevention of incipient failures.
Mean time between failure (MTBF) – A basic measure of reliability for repairable items:the mean number of life units during which all parts of the item perform within their specified limits, during a particular measurement interval under stated conditions.
Mean time to failure (MTTF) – A basic measure of reliability for non-repairable items:The mean number of life units during which all parts of the item perform within their specified limits, during a particular measurement interval under stated conditions.
Mean time to repair (MTTR) – A basic measure of maintainability:the sum of corrective maintenance times at any specified level of repair, divided by the total number of failures within an item repaired at that level, during a particular interval under stated conditions.
Mission reliability – The ability of an item to perform its required functions for the duration of specified mission profile.
신뢰성 – (1) The duration or probability of failure-free performance under stated conditions. (2) The probability that an item can perform its intended function for a specified interval under stated conditions. For non-redundant items this is the equivalent to definition (1). For redundant items, this is the definition of mission reliability.
장비 유지 보수 및 수리
사람은 도구만큼 훌륭하다는 오래된 속담이 있습니다. 이것은 정확성과 효율성이 성공에 중요한 모든 공예 또는 산업에 해당됩니다. 이것이 특히 잘 적용되는 산업 중 하나는 신뢰성 엔지니어링입니다.Camcode에서 제공하는 창고 및 산업 자산 관리 제품은 많은 신뢰성 엔지니어에 의해 설계, 생성 및 사용되기 때문에 신뢰성 요구 사항에 대해 더 알고 싶었습니다. 엔지니어, 특히 신뢰성 엔지니어가 설계 및 엔지니어링 프로세스를 위해 갖추어야 할 필수 도구는 무엇입니까? 이를 위해 우리는 신뢰성 엔지니어링 전문가 패널에게 다음과 같은 질문을
전자 부품의 절반 이상이 열 환경으로 인한 높은 스트레스로 인해 고장나는 것으로 추정됩니다. 최근 몇 년 동안 대규모 및 하이퍼스케일 집적 회로(IC) 및 표면 실장 기술(SMT)의 광범위한 장치와 전자 제품이 소형화, 고밀도 및 고신뢰성을 향한 개발 방향을 수용하기 시작하는 것을 목격했습니다. 따라서 전자 시스템은 열 성능에 대한 요구 사항이 점점 더 높아지고 있습니다. 결국 전자 제품의 출현과 함께 탄생한 열 관리는 전자 시스템의 성능과 기능을 결정하는 중요한 역할을 합니다. 전자 기기의 근간인 PCB(Printed Circ