저는 최근에 실리콘 밸리에서 열린 2018 Xilinx Development Forum(XDF)에 참석했습니다. 이 포럼에서 저는 FPGA(Field Programmable Gate Array)와 관련된 AI 관련 문제를 해결했다고 주장하는 인공 지능(AI) 분야의 스타트업인 Mipsology라는 회사를 소개받았습니다. Mipsology는 배치에 내재된 제약 없이 FPGA에서 달성할 수 있는 최고 성능으로 모든 NN(신경망)의 계산을 가속화한다는 원대한 비전을 가지고 설립되었습니다.
Mipsology는 Xilinx에서 새로 발표한 Alveo 보드에서 실행되고 ResNet50, InceptionV3, VGG19 등을 포함한 NN 컬렉션을 처리하면서 초당 20,000개 이상의 이미지를 실행하는 능력을 보여주었습니다.
신경망 및 딥 러닝 소개 인간 두뇌의 뉴런 웹에서 느슨하게 모델링된 신경망은 자체적으로 작업을 학습할 수 있는 복잡한 수학 시스템인 딥 러닝(DL)의 기초입니다. 많은 예나 연관성을 살펴보면 NN은 배울 수 있습니다 전통적인 인식 프로그램보다 더 빠른 연결 및 관계. 학습 을 기반으로 특정 작업을 수행하도록 NN을 구성하는 프로세스 같은 유형의 수백만 개의 샘플을 교육 이라고 합니다. .
예를 들어 NN은 많은 보컬 샘플을 듣고 DL을 사용하여 특정 단어의 소리를 "인식"하는 방법을 배울 수 있습니다. 그런 다음 이 NN은 새로운 보컬 샘플 목록을 살펴보고 추론 이라는 기술을 사용하여 학습한 단어가 포함된 샘플을 올바르게 식별할 수 있습니다. .
복잡성에도 불구하고 DL은 수십억 또는 수조의 간단한 연산(대부분 덧셈과 곱셈)을 수행하는 것을 기반으로 합니다. 이러한 작업을 수행하기 위한 계산 요구는 벅차다. 보다 구체적으로, DL 추론을 실행하기 위한 컴퓨팅 요구 사항은 DL 교육을 위한 것보다 더 큽니다. DL 교육은 한 번만 수행되어야 하는 반면, NN은 한 번 교육되면 수신하는 각각의 새 샘플에 대해 계속해서 추론을 수행해야 합니다.
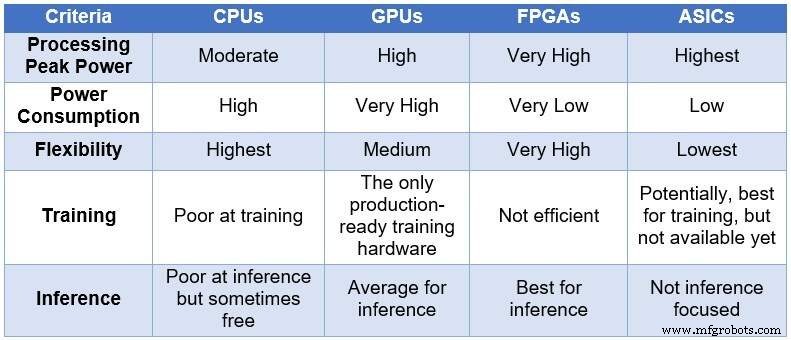
딥 러닝 추론을 가속화하기 위한 4가지 선택 시간이 지남에 따라 엔지니어링 커뮤니티는 NN을 처리하기 위해 4개의 다른 컴퓨팅 장치에 의존했습니다. 처리 능력과 전력 소비는 증가하고 유연성/적응성은 감소하는 순서로 이러한 장치에는 중앙 처리 장치(CPU), 그래픽 처리 장치(GPU), FPGA 및 ASIC(주문형 집적 회로)가 포함됩니다. 아래 표에는 4가지 컴퓨팅 장치 간의 주요 차이점이 요약되어 있습니다.
<중앙> DL 컴퓨팅을 위한 CPU, GPU, FPGA 및 ASIC 비교(출처:Lauro Rizzatti)
CPU는 Von Neuman 아키텍처를 기반으로 합니다. CPU는 유연하지만(존재하는 이유) 간단한 작업을 실행하기 위해 여러 클록 주기를 소모하는 메모리 액세스로 인해 긴 대기 시간의 영향을 받습니다. NN 계산, 특히 DL 교육 및 추론과 같이 대기 시간이 가장 짧은 작업에 적용할 때 가장 좋지 않은 선택입니다.
GPU는 유연성이 떨어지는 대신 높은 계산 처리량을 제공합니다. 또한 GPU는 냉각을 요구하는 상당한 전력을 소비하므로 데이터 센터에 배포하기에 적합하지 않습니다.
맞춤형 ASIC이 이상적인 솔루션처럼 보일 수 있지만 고유한 문제가 있습니다. ASIC을 개발하는 데는 몇 년이 걸립니다. DL과 NN은 지속적인 혁신을 통해 빠르게 진화하고 있어 작년의 기술은 의미가 없습니다. 또한 CPU나 GPU와 경쟁하려면 ASIC이 가장 얇은 공정 노드 기술을 사용하는 넓은 실리콘 영역을 사용해야 합니다. 이것은 장기적인 관련성을 보장하지 않고 선행 투자를 비싸게 만듭니다. 모든 것을 고려하면 ASIC은 특정 작업에 효과적입니다.
FPGA 디바이스는 추론을 위한 최상의 선택으로 부상했습니다. 빠르고 유연하며 전력 효율적이며 데이터 센터, 특히 빠르게 변화하는 DL 세계, 네트워크 에지 및 AI 과학자의 책상 아래에서 데이터 처리를 위한 우수한 솔루션을 제공합니다.
오늘날 사용 가능한 가장 큰 FPGA에는 수백만 개의 단순 부울 연산자, 수천 개의 메모리와 DSP, 여러 CPU ARM 코어가 포함됩니다. 이러한 모든 리소스는 병렬로 작동합니다. 각 클럭 틱은 최대 수백만 개의 동시 작업을 트리거하므로 초당 수조 개의 작업이 수행됩니다. DL에 필요한 처리는 FPGA 리소스에 매우 잘 매핑됩니다.
FPGA는 다음을 포함하여 DL에 사용되는 CPU 및 GPU에 비해 다른 이점이 있습니다.
특정 유형의 데이터에 국한되지 않습니다. DL에 대해 더 높은 처리량을 제공하는 데 더 적합한 비표준 낮은 정밀도를 처리할 수 있습니다.
CPU나 GPU보다 전력을 덜 사용합니다. 일반적으로 동일한 NN 계산에 대해 평균 전력이 5~10배 적습니다. 데이터 센터의 반복 비용이 더 낮습니다.
모든 작업에 맞게 다시 프로그래밍할 수 있지만 다양한 작업을 수용할 수 있을 만큼 충분히 일반적입니다. DL은 빠르게 발전하고 있으며 동일한 FPGA는 차세대 실리콘(ASIC에서 일반적임) 없이 새로운 요구 사항을 충족하므로 소유 비용을 절감할 수 있습니다.
대형 기기에서 소형 기기까지 다양합니다. 데이터 센터나 사물 인터넷(IoT) 노드에서 사용할 수 있습니다. 유일한 차이점은 포함된 블록의 수입니다.
반짝이는 것이 모두 금은 아닙니다 FPGA의 높은 연산 능력, 낮은 전력 소비 및 유연성에는 프로그래밍의 어려움이라는 대가가 따릅니다.