

임베디드

산업 제조
머신 러닝과 딥 러닝은 이미 우리 삶의 필수적인 부분입니다. 자연어 처리(NLP), 이미지 분류 및 객체 감지를 통한 인공 지능(AI) 애플리케이션은 우리가 사용하는 많은 장치에 깊이 내장되어 있습니다. 대부분의 AI 애플리케이션은 Gmail에서 이메일 응답을 입력할 때 단어 예측을 받는 것과 같이 사용 용도에 잘 맞는 클라우드 기반 엔진을 통해 제공됩니다.
이러한 AI 애플리케이션의 이점을 누리는 만큼 이 접근 방식은 개인 정보 보호, 전력 손실, 대기 시간 및 비용 문제를 야기합니다. 데이터 자체의 출처에서 부분 또는 전체 계산(추론)을 수행할 수 있는 로컬 처리 엔진이 있으면 이러한 문제를 해결할 수 있습니다. 이것은 메모리가 전력을 많이 소모하는 병목 현상이 되는 기존의 디지털 신경망 구현에서는 수행하기 어려웠습니다. 이 문제는 다중 레벨 메모리와 아날로그 인메모리 컴퓨팅 방법을 사용하여 해결할 수 있습니다. 이 방법을 사용하면 처리 엔진이 AI 추론을 수행하기 위한 훨씬 낮은 밀리와트(mW) ~ 마이크로와트(uW) 전력 요구 사항을 충족할 수 있습니다. 네트워크 에지.
클라우드 컴퓨팅의 과제
AI 애플리케이션이 클라우드 기반 엔진을 통해 제공될 때 사용자는 컴퓨팅 엔진이 데이터를 처리하는 클라우드에 일부 데이터를 (의지 여부에 관계없이) 업로드해야 하며, 예측을 제공하고 사용자가 소비할 예측을 다운스트림으로 보내야 합니다.

그림 1:에지에서 클라우드로의 데이터 전송. (출처:Microchip Technology)
이 프로세스와 관련된 문제는 다음과 같습니다.
로컬 처리 엔진을 사용하여 이러한 문제를 해결하려면 추론 작업을 수행할 신경망 모델이 먼저 원하는 사용 사례에 대해 주어진 데이터 세트로 훈련되어야 합니다. 일반적으로 이를 위해서는 높은 컴퓨팅(및 메모리) 리소스와 부동 소수점 산술 연산이 필요합니다. 결과적으로 머신 러닝 솔루션의 훈련 부분은 최적의 신경망 모델을 생성하기 위해 데이터 세트와 함께 퍼블릭 또는 프라이빗 클라우드(또는 로컬 GPU, CPU, FPGA 팜)에서 여전히 수행되어야 합니다. 신경망 모델이 준비되면, 신경망 모델은 추론 작업을 위해 역전파가 필요하지 않기 때문에 작은 컴퓨팅 엔진으로 로컬 하드웨어에 대해 모델을 더욱 최적화할 수 있습니다. 추론 엔진에는 일반적으로 다양한 MAC(Multiply-Accumulate) 엔진이 필요하며, 그 다음에는 신경망 모델 복잡성에 따라 ReLU(Rectified Linear Unit), Sigmoid 또는 tanh와 같은 활성화 레이어와 레이어 사이의 풀링 레이어가 필요합니다.
대부분의 신경망 모델에는 방대한 양의 MAC 작업이 필요합니다. 예를 들어, 비교적 작은 '1.0 MobileNet-224' 모델도 420만 개의 매개변수(가중치)를 갖고 추론을 수행하기 위해 5억 6900만 MAC 연산이 필요합니다. 대부분의 모델이 MAC 작업에 의해 지배되기 때문에 여기서는 기계 학습 계산의 이 부분에 초점을 맞추고 더 나은 솔루션을 만들 수 있는 기회를 탐색합니다. 단순하고 완전히 연결된 2계층 네트워크가 아래 그림 2에 나와 있습니다.
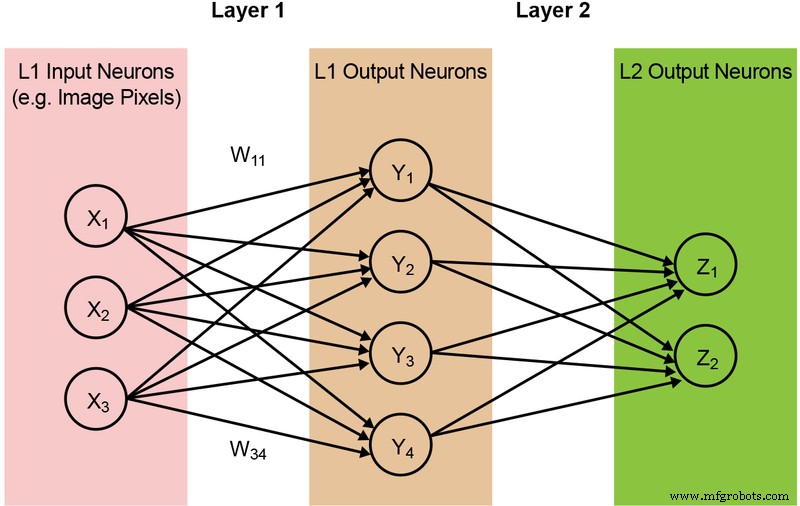
그림 2:두 개의 레이어가 있는 완전히 연결된 신경망. (출처:Microchip Technology)
입력 뉴런(데이터)은 첫 번째 가중치 레이어로 처리됩니다. 그런 다음 첫 번째 레이어의 출력 뉴런이 두 번째 가중치 레이어로 처리되고 예측을 제공합니다(예:모델이 주어진 이미지에서 고양이 얼굴을 찾을 수 있는지 여부). 이러한 신경망 모델은 다음 방정식으로 설명된 모든 계층의 모든 뉴런 계산에 '내적'을 사용합니다(단순화를 위해 방정식에서 '편향' 용어 생략).
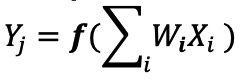
기억 디지털 컴퓨팅의 병목 현상
디지털 신경망 구현에서 가중치와 입력 데이터는 DRAM/SRAM에 저장됩니다. 추론을 위해 가중치와 입력 데이터를 MAC 엔진으로 이동해야 합니다. 아래 그림 3과 같이 이 접근 방식을 사용하면 실제 MAC 작업이 수행되는 ALU에 데이터를 입력하고 모델 매개변수를 가져오는 데 대부분의 전력이 소모됩니다.
그림 3:기계 학습 계산의 메모리 병목 현상. (출처:Y.-H. Chen, J. Emer, V. Sze, "Eyeriss:A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks," in ISCA, 2016)
에너지 관점에서 보면 디지털 논리 게이트를 사용하는 일반적인 MAC 작업은 ~250펨토줄(fJ 또는 10 −15 joules)의 에너지이지만 데이터 전송 중에 소산되는 에너지는 계산 자체보다 2배 이상 크고 50피코줄(pJ 또는 10 −12 ) 범위에 있습니다. 줄) ~ 100pJ. 공정하게 말하면 메모리에서 ALU로의 데이터 전송을 최소화하는 데 사용할 수 있는 많은 설계 기술이 있습니다. 그러나 전체 디지털 방식은 여전히 Von Neumann 아키텍처에 의해 제한됩니다. 따라서 이는 낭비되는 전력을 줄일 수 있는 큰 기회를 제공합니다. MAC 작업을 수행하기 위한 에너지를 ~100pJ에서 pJ의 일부로 줄일 수 있다면 어떨까요?
아날로그 인메모리 컴퓨팅으로 메모리 병목 현상 제거
메모리 자체를 사용하여 계산에 필요한 전력을 줄일 수 있을 때 에지에서 추론 작업을 수행하면 전력 효율성이 높아집니다. 인메모리 컴퓨팅 방법을 사용하면 이동해야 하는 데이터의 양이 최소화됩니다. 이것은 차례로 데이터 전송 중에 낭비되는 에너지를 제거합니다. 매우 낮은 유효 전력 손실로 작동할 수 있는 플래시 셀을 사용하여 에너지 손실을 더욱 최소화하고 대기 모드에서 에너지 손실이 거의 없습니다.
이 접근 방식의 예로는 Microchip Technology 회사인 SST(Silicon Storage Technology)의 memBrain™ 기술이 있습니다. SST의 SuperFlash ® 기반 메모리 기술을 사용하는 이 솔루션에는 추론 모델의 가중치가 저장된 위치에서 계산을 수행할 수 있는 인메모리 컴퓨팅 아키텍처가 포함됩니다. 이것은 가중치에 대한 데이터 이동이 없기 때문에 MAC 계산에서 메모리 병목 현상을 제거합니다. 카메라나 마이크와 같은 입력 센서에서 메모리 어레이로 입력 데이터만 이동하면 됩니다.
이 메모리 개념은 두 가지 기본 사항을 기반으로 합니다. (a) 트랜지스터의 아날로그 전류 응답은 임계 전압(Vt) 및 입력 데이터를 기반으로 합니다. (b) Kirchhoff의 전류 법칙은 한 지점에서 만나는 지휘자의 네트워크는 0입니다.
이 다중 레벨 메모리 아키텍처에 사용되는 기본 NVM(비휘발성 메모리) 비트셀을 이해하는 것도 중요합니다. 아래 다이어그램(그림 4)은 두 개의 ESF3(Embedded SuperFlash 3 rd 세대) 비트셀은 EG(Erase Gate) 및 SL(소스 라인)을 공유합니다. 각 비트셀에는 5개의 터미널이 있습니다:Control Gate(CG), Work Line(WL), Erase Gate(EG), Source Line(SL) 및 Bitline(BL). 비트셀의 소거 동작은 EG에 고전압을 인가함으로써 이루어진다. 프로그래밍 동작은 WL, CG, BL, SL에 고/저 전압 바이어스 신호를 인가하여 수행됩니다. 읽기 동작은 WL, CG, BL, SL에 저전압 바이어스 신호를 인가하여 수행됩니다.
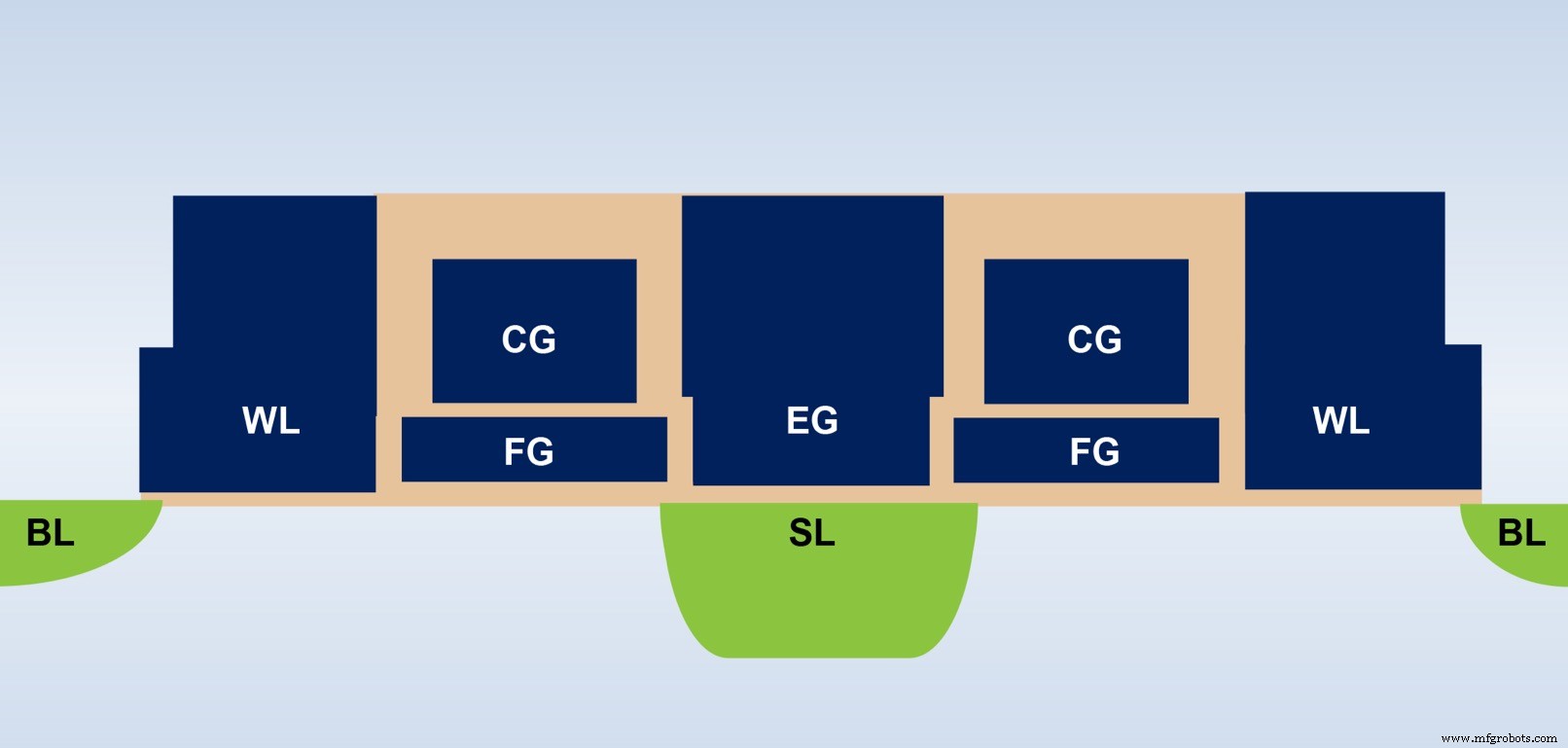
그림 4:SuperFlash ESF3 셀. (출처:Microchip Technology)
이 메모리 아키텍처를 통해 사용자는 세분화된 프로그래밍 작업을 통해 다양한 Vt 레벨에서 메모리 비트셀을 프로그래밍할 수 있습니다. 메모리 기술은 입력 전압에서 특정 전류 응답을 달성하기 위해 메모리 셀의 부동 게이트(FG) Vt를 조정하는 스마트 알고리즘을 사용합니다. 최종 애플리케이션의 요구 사항에 따라 셀을 선형 또는 하위 임계값 작동 영역에서 프로그래밍할 수 있습니다.
그림 5는 메모리 셀에 여러 레벨을 저장하고 읽는 기능을 보여줍니다. 메모리 셀에 2비트 정수 값을 저장하려고 한다고 가정해 보겠습니다. 이 시나리오에서는 2비트 정수 값(00, 01, 10, 11)의 4가지 가능한 값 중 하나로 메모리 배열의 각 셀을 프로그래밍해야 합니다. 아래의 4개 곡선은 4가지 가능한 상태 각각에 대한 IV 곡선이며 셀의 전류 응답은 CG에 적용된 전압에 따라 달라집니다.
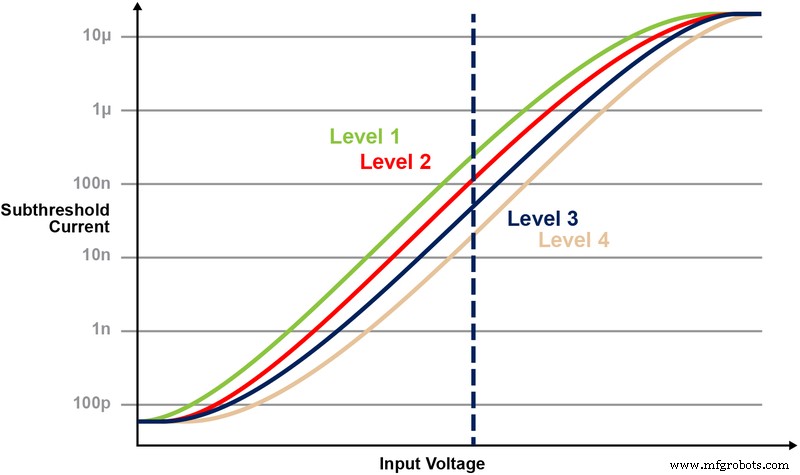
그림 5:ESF3 셀에서 Vt 레벨 프로그래밍. (출처:Microchip Technology)
인메모리 컴퓨팅을 사용한 곱셈 누산 연산
각 ESF3 셀은 가변 컨덕턴스(gm ). ESF3 셀의 컨덕턴스는 프로그래밍된 셀의 플로팅 게이트 Vt에 따라 달라집니다. 훈련된 모델의 가중치는 메모리 셀의 부동 게이트 Vt로 프로그래밍되므로 gm 셀의 는 훈련된 모델의 가중치를 나타냅니다. ESF3 셀에 입력 전압(Vin)이 인가되면 출력 전류(Iout)는 Iout =gm 방정식으로 주어집니다. * Vin은 입력 전압과 ESF3 셀에 저장된 가중치를 곱한 연산입니다.
아래 그림 6은 동일한 열(예:I1 =I11 + I21). 애플리케이션에 따라 활성화 기능은 ADC 블록 내에서 수행되거나 메모리 블록 외부에서 디지털 구현으로 수행될 수 있습니다.
더 큰 이미지를 보려면 클릭하세요.
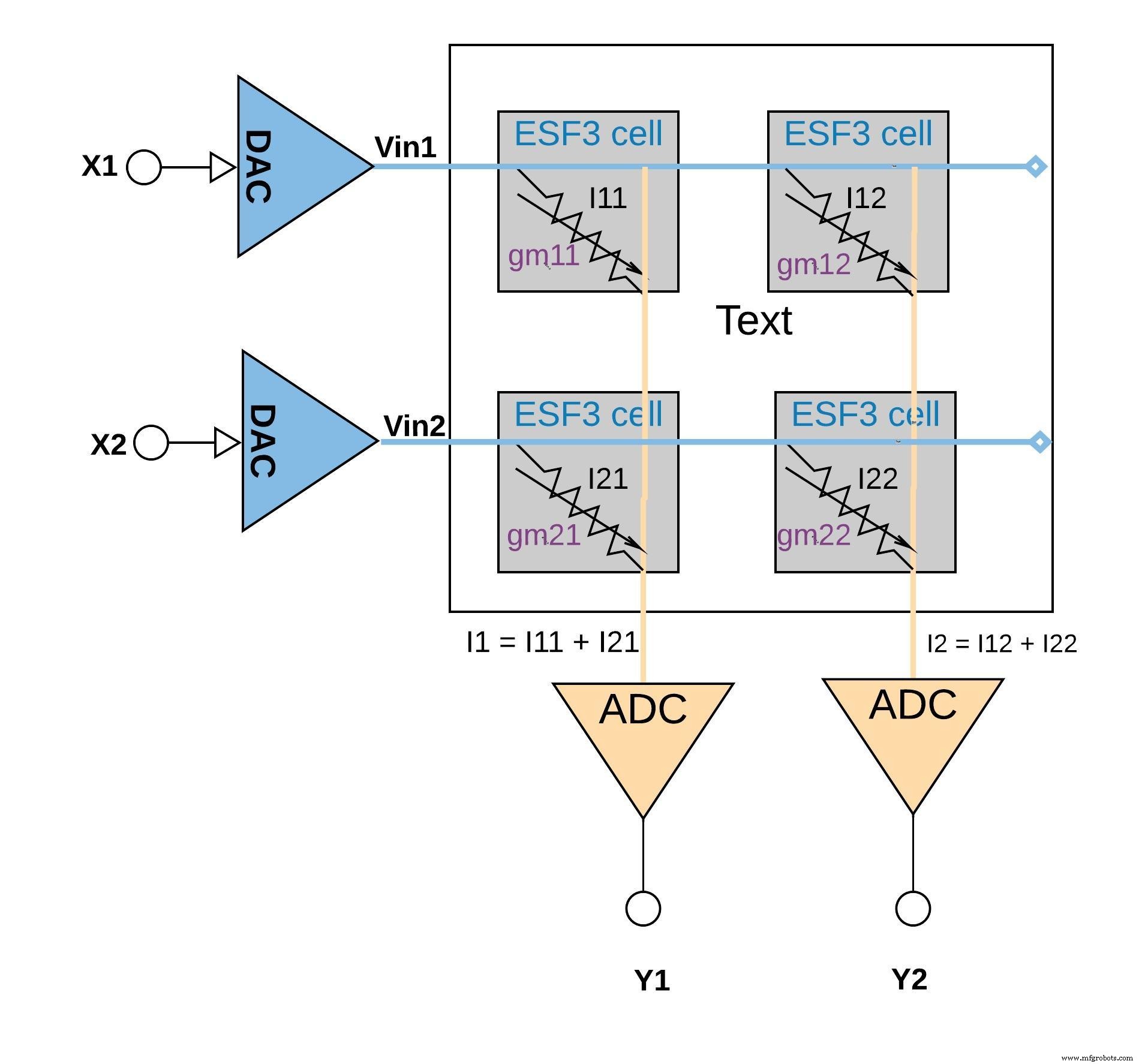
그림 6:ESF3 어레이(2×2)를 사용한 곱셈 누산 연산. (출처:Microchip Technology)
개념을 더 높은 수준에서 더 자세히 설명하기 위해; 훈련된 모델의 개별 가중치는 메모리 셀의 부동 게이트 Vt로 프로그래밍되므로 훈련된 모델의 각 계층(완전 연결 계층이라고 가정)의 모든 가중치는 물리적으로 가중치 행렬처럼 보이는 메모리 어레이에 프로그래밍할 수 있습니다. , 그림 7과 같이
더 큰 이미지를 보려면 클릭하세요.
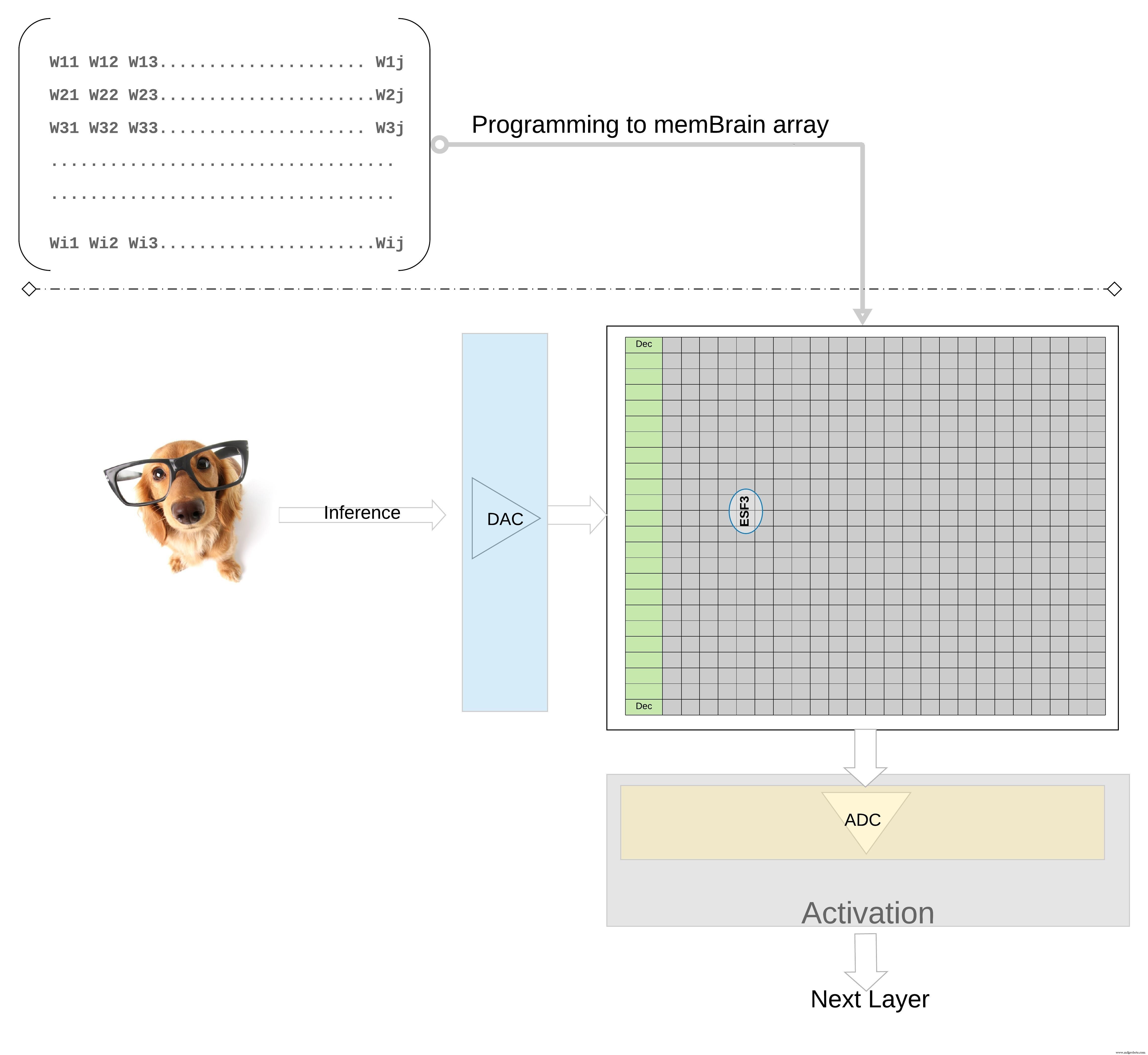
그림 7:추론을 위한 가중치 매트릭스 메모리 어레이. (출처:Microchip Technology)
추론 작업의 경우 디지털 입력, 예를 들어 이미지 픽셀이 먼저 DAC(디지털-아날로그 변환기)를 사용하여 아날로그 신호로 변환되고 메모리 어레이에 적용됩니다. 그런 다음 어레이는 주어진 입력 벡터에 대해 병렬로 수천 개의 MAC 연산을 수행하고 각 뉴런의 활성화 단계로 갈 수 있는 출력을 생성합니다. 그러면 아날로그-디지털 변환기(ADC)를 사용하여 디지털 신호로 다시 변환될 수 있습니다. 그런 다음 디지털 신호는 다음 레이어로 이동하기 전에 풀링을 위해 처리됩니다.
이러한 유형의 메모리 아키텍처는 매우 모듈화되고 유연합니다. 많은 memBrain 타일을 함께 연결하여 가중치 행렬과 뉴런이 혼합된 다양한 대형 모델을 구축할 수 있습니다(그림 8 참조). 이 예에서 3×4 타일 구성은 아날로그 및 디지털 패브릭으로 연결됩니다. 타일 및 데이터는 공유 버스를 통해 한 타일에서 다른 타일로 이동할 수 있습니다.
더 큰 이미지를 보려면 클릭하세요.
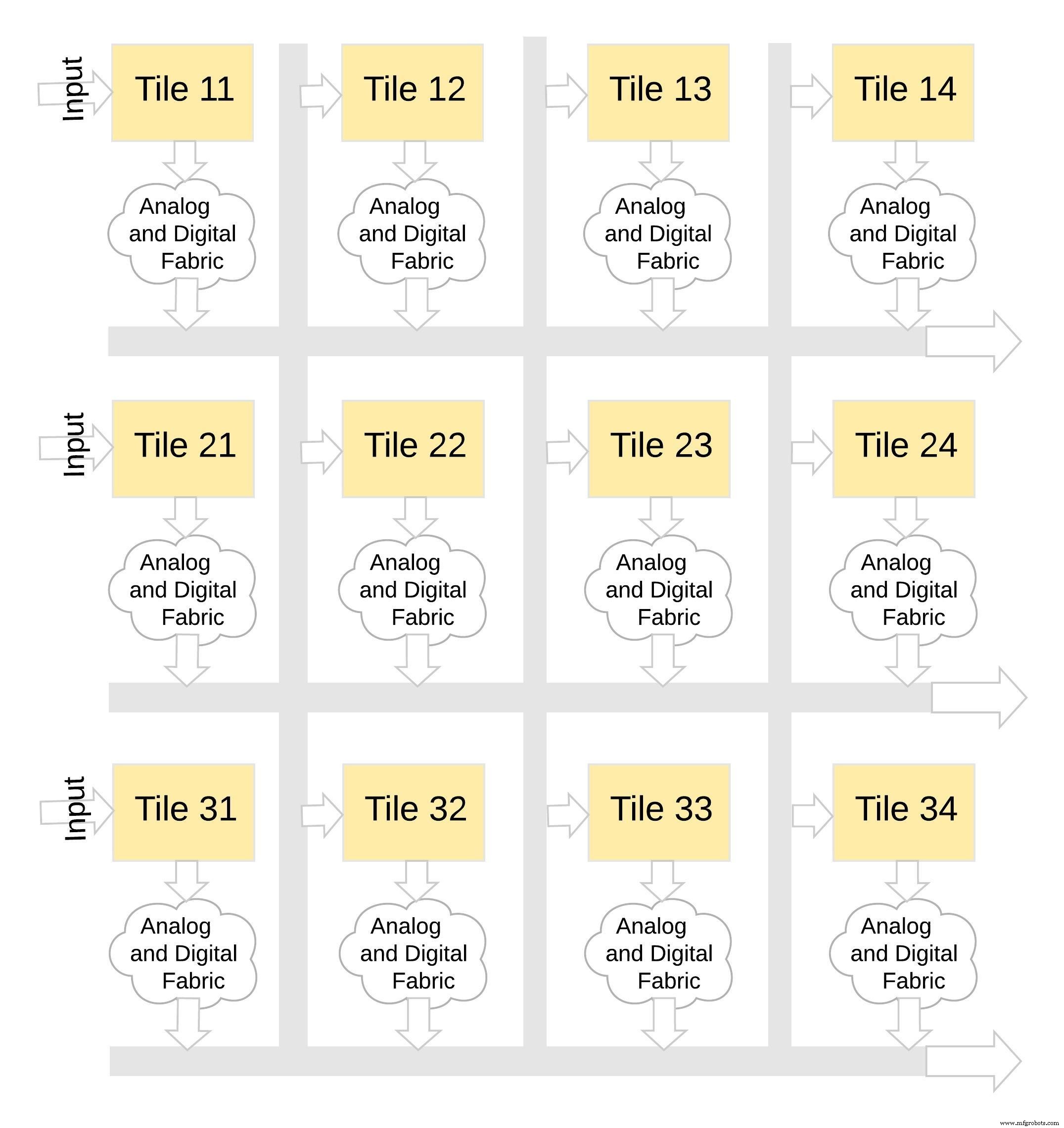
그림 8:memBrain™은 모듈식입니다. (출처:Microchip Technology)
지금까지 우리는 주로 이 아키텍처의 실리콘 구현에 대해 논의했습니다. 소프트웨어 개발 키트(SDK)의 가용성(그림 9)은 솔루션 배포에 도움이 됩니다. SDK는 실리콘 외에도 추론 엔진의 배포를 용이하게 합니다.
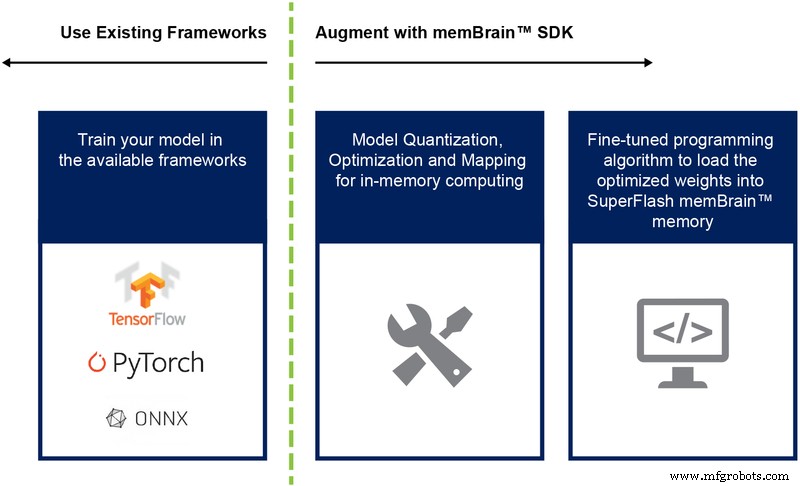
그림 9:memBrain™ SDK 흐름. (출처:Microchip Technology)
SDK 흐름은 학습 프레임워크에 구애받지 않습니다. 사용자는 원하는 대로 부동 소수점 계산을 사용하여 TensorFlow, PyTorch 또는 기타와 같은 사용 가능한 프레임워크에서 신경망 모델을 만들 수 있습니다. 모델이 생성되면 SDK는 훈련된 신경망 모델을 양자화하고 이를 메모리 어레이에 매핑하는 데 도움이 됩니다. 여기서 센서 또는 컴퓨터에서 오는 입력 벡터로 벡터-행렬 곱셈을 수행할 수 있습니다.
결론
인메모리 컴퓨팅 기능을 갖춘 이 다단계 메모리 접근 방식의 장점은 다음과 같습니다.
에지 컴퓨팅 애플리케이션은 큰 가능성을 보여줍니다. 그러나 엣지 컴퓨팅이 본격화되기 전에 해결해야 할 전력 및 비용 문제가 있습니다. 플래시 셀에서 온칩 계산을 수행하는 메모리 접근 방식을 사용하면 주요 장애물을 제거할 수 있습니다. 이 접근 방식은 기계 학습 응용 프로그램에 최적화된 실제 표준 유형의 다단계 메모리 기술 솔루션으로 입증되었습니다.
임베디드
스마트 자동차, 스마트 홈 장치 및 연결된 산업 장비의 수와 인기가 증가함에 따라 거의 모든 곳에서 데이터를 생성합니다. 실제로 2022년에는 전 세계적으로 164억 개 이상의 IoT(사물 인터넷) 장치가 연결되어 있으며 그 수는 2025년까지 309억 개까지 급증할 것으로 예상됩니다. 그때까지 IDC는 이러한 장치가 전 세계적으로 73.1제타바이트의 데이터를 생성할 것으로 예측합니다. 멀지 않은 2019년에 비해 300% 성장했습니다. 이 데이터를 빠르고 효과적으로 정렬하고 분석하는 것은 최적의 애플리케이션 사용자 경험과 더
빅 데이터는 연결된 장치에서 수집된 방대한 데이터 세트를 의미하며 이를 분석하여 데이터 기반 인사이트를 생성합니다. 업계 리더는 빅 데이터를 사용하여 패턴과 소비자 행동을 식별하고 과거 추세를 분석하여 운영 효율성을 최적화하고 비즈니스 관행을 개선합니다. 일부 통계 분석 및 일부 소비자 조사, 빅 데이터는 가치 창출의 핵심입니다. 특히 제조 부문에서는 실행 가능한 빅 데이터 통찰력을 활용하는 것이 시간과 비용을 더 많이 절약하는 열쇠가 될 수 있습니다. Honeywell과 KRC가 수행한 공동 연구에 따르면 빅 데이터 분석을 효과