

임베디드

산업 제조
자동화는 미래의 길입니다. 우리는 모든 것이 응답되고 성취되고 빠른 속도로 받기를 바라는 시대에 살고 있습니다. 이러한 근본적인 변화에도 불구하고 많은 사람들이 기술을 수용하지 않습니다. 어떤 사람들에게는 라이프스타일과 관련이 있습니다. 대기업은 시스템을 변환하기에는 너무 어설프고 개인은 터치 스크린을 탐색하는 방법을 배우고 싶어하지 않는 방식에 갇힐 수 있습니다. 그러나 대부분의 경우 데이터 소유자와 보안 유지 방법이 중요합니다.
해결책? 음성처럼 간단합니다. 음성 지원 기술은 데이터를 가깝게 유지하면서 자동화의 필요성을 해소할 수 있으며 장소나 플랫폼에 관계없이 우리가 매일 사용하는 것입니다. 디지털 혁신이 점점 더 많은 애플리케이션에 계속 영향을 미치면서 음성 에이전트가 해답입니다. Alexa 및 Google Voice와 같은 인기 있는 음성 에이전트 이름 외에도 기술에 내장된 맞춤형 음성 플랫폼 구축을 모색하는 기업이 늘어나고 있습니다. 고유한 음성 플랫폼은 자체 데이터를 유지하고 제어하려는 기업을 위한 방법이 될 것입니다.
중단의 배후에는 자동화가 있습니다.
사물 인터넷(IoT)이 인공 지능(AI)을 기반으로 구축됨에 따라 자동화의 필요성이 증가하기 시작했습니다. IoT가 AI와 협력하면 광대하고 광범위한 인터넷 장치 컬렉션에 대한 사용자의 제어가 향상됩니다. Google Voice, Amazon Alexa, Microsoft Cortana 또는 고유하게 생성된 플랫폼과 같은 플랫폼을 통해 인터페이스하는 음성 지원이 가정과 그 이상으로 확장되는 것을 보기 시작했습니다. Harman Embedded Audio에서 우리는 지구상의 모든 단일 음성 엔진과 협력했으며 시장의 폭을 직접 이해했습니다. 데이터를 제어할 수 있도록 자체 맞춤형 음성 지원 플랫폼에서 음성 지원 제품을 구축하려는 회사가 더 많이 있습니다.
음성 제어에 대한 수요 증가
오디오에서 가장 핫한 트렌드 중 하나입니다. 터치 스크린과 같은 기능이 거의 유비쿼터스에 가까운 사용자 인터페이스에서 다음으로 중요한 것은 장치와 대화할 수 있다는 것입니다. 보이스는 차세대 인간 협업을 주도하고 있습니다. 컴퓨터에서의 자연어 처리를 생각해 보십시오. 음성은 기계가 듣기에 적합한 방식으로 처리되지만 동일한 처리된 파일을 재생하면 기계적이고 부자연스럽습니다. 전화 통화도 마찬가지입니다. 누군가와 함께 방에 있는 것과 같은 느낌을 주지는 않습니다. 이것이 음성이 필요한 곳이며 위에서 언급한 고유한 음성 플랫폼이 따라야 할 곳입니다.
맞춤형 음성 에이전트의 모양 및 빌드와 관련된 내용
모든 음성 솔루션은 다르지만 모든 솔루션이 사용자 데이터를 수집하고 보호하면서 사용 사례의 필수 요구 사항에 적응할 수 있을 만큼 충분히 유연해야 합니다. 이를 달성하기 위해 모든 음성 에이전트의 구축 및 통합과 관련된 세 가지 주요 요소가 있습니다.
첫 번째는 원거리 알고리즘입니다. 원거리 음성을 캡처하는 최상위 알고리즘을 사용합니다. 우리 회사에서는 소음 억제, 음향 소음 제거, 소리 분리 및 빔 형성, 음성 활동 감지 등 Sonique 알고리즘의 4가지 주요 소프트웨어 알고리즘을 사용합니다. 이러한 알고리즘은 음성 지원 애플리케이션을 지원하기 위해 서로 조합하여 사용하도록 특별히 개발되었습니다.
그들은 어떻게 작동합니까? 스마트 스피커를 사람과 비교한다고 생각해 보십시오. DSP/SOC는 화자의 '두뇌' 역할을 하고 마이크는 귀, 화자는 입입니다. 우리의 경우 누군가가 우리의 이름을 부르면 우리의 뇌는 우리 주변의 모든 소음을 취소하고 그 키워드에 모든 에너지를 쏟습니다. 이것이 우리가 스마트 스피커에서 달성한 것입니다. 키워드가 감지되면 마이크는 다양한 소음 억제 기술을 사용하고 모든 전력을 소스에 집중합니다. 그 과정에서 주변 소음을 대부분 제거합니다. 음향 환경에는 주변 소음, 로컬 스피커, HVAC 등과 같이 스피커에서 마이크까지 피드백을 에코하는 많은 소음원이 있습니다. 이러한 각 소음원에는 고유한 개별 솔루션이 필요합니다. Sonique 알고리즘은 소음을 억제하고 가능한 최상의 명확한 음성 명령을 캡처합니다.
또한 키워드 스포팅(KWS) 엔진을 구축하는 것이 중요합니다. KWS는 "Alexa" 또는 "OK Google"과 같은 키워드를 감지하여 대화를 시작합니다. 저는 거의 모든 KWS 엔진 제공업체와 협력했으며 각 제공업체는 심층 신경망으로 구동됩니다. 고도로 사용자 정의가 가능하고, 항상 듣고, 가볍고, 내장되어 있습니다. 원거리 음성 응용 프로그램에서 훌륭한 고객 경험을 위해 중요한 구성 요소는 False Accept 및 False Reject 비율입니다. 실제 상황에서 오디오 재생의 불완전한 취소를 유발하는 TV, 가전 제품, 샤워 등과 같은 많은 외부 소음이 있기 때문에 낮은 False Reject 비율을 유지하는 것은 정말 어렵습니다. 숙련된 개발자는 False Accept Rate를 낮게 유지하기 위해 KWS 엔진을 조정합니다.
마지막으로 ASR(자동 음성 인식) 엔진이 음성을 텍스트로 변환합니다. ASR은 핵심 STT(음성 텍스트 변환) 도구와 원시 텍스트를 데이터로 변환하는 자연어 이해(NLU)로 구성됩니다. 엔진은 또한 기술, 즉 답변을 제공할 수 있는 지식 기반과 역텍스트 음성 변환 도구를 필요로 합니다. 예를 들어 우리는 E-NOVA라는 ASR 엔진을 개발했습니다. 이 엔진은 다중 플랫폼, 온프레미스 통합을 제공하고, 여러 언어(현재 7개 언어 및 계속 증가하고 있음)를 지원하고, 학습 가능한 모델, 타사 통합 지원 및 발화자 식별을 포함합니다.
ASR은 Amazon Alexa, OK Google, Cortana 또는 고객과 같은 음성 기술이 "로스앤젤레스 날씨는 어떤가요?"라는 질문에 응답할 수 있도록 하는 첫 번째 단계입니다. 말하는 소리를 감지하여 단어로 인식하여 주어진 언어의 소리와 매칭시켜 궁극적으로 우리가 말하는 단어를 식별하는 핵심 부품입니다. ASR 엔진 덕분에 대화가 자연스럽게 느껴진다. 그리고 최신 기술을 통해 대부분의 ASR 엔진은 클라우드 컴퓨팅을 활용합니다. NLU와 같은 추가 기술로 인간과 컴퓨터 간의 대화는 점점 더 똑똑해지고 복잡해지고 있습니다.
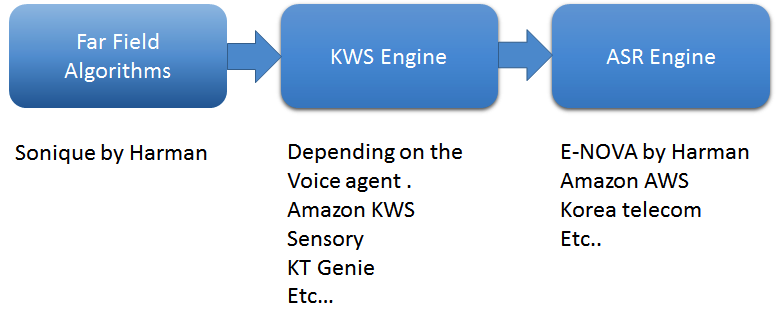
그림 1:음성 에이전트의 기본 처리 파이프라인. (출처:Harman Embedded Audio)
그러나 맞춤형 음성 에이전트를 구축하는 것은 여러 가지 고유한 과제를 안고 있습니다. 제품 환경을 이해하는 것은 프로세스의 주요 과제 중 하나이며 각 애플리케이션은 특정 사용 사례에 따라 다릅니다. 예를 들어 집에서 요리를 하고 손이 바쁘고 배부른데 물을 끓일 시간이 되면 배관에 연결된 음성 에이전트에 "물을 x도까지 끓여주세요"라고 빠르게 요청하기만 하면 됩니다. 여기서 문제는 장치가 사용자의 말을 들을 수 있는지 여부와 깨끗한 신호를 수신하고 사용자의 말을 제대로 들을 수 있도록 장치가 얼마나 많은 소음을 제거할 것인지입니다. 이를 위해 음성 알고리즘은 적대적인 환경에 맞게 조정되어야 하고 마이크 위치는 소리를 포착할 수 있도록 조정되어야 하며 낮은 THD 스피커를 사용하여 마이크의 높은 SNR을 지원해야 합니다. 이를 통해 ASR 엔진에 가능한 가장 선명한 오디오를 제공하여 질문에 대한 올바른 답변을 얻을 수 있습니다.
또한 유람선에 있다고 상상해보십시오. 주변 소음은 거실이나 주방에서 들리는 소리와 완전히 다릅니다. 가장 큰 과제는 이러한 노이즈를 억제하고 정확한 응답을 위해 시스템에 깨끗한 오디오 신호를 제공하는 알고리즘을 훈련시키는 것입니다. MSC Cruises를 위해 개발한 것과 같은 가상 개인 크루즈 보조 시스템을 적절히 구현하면 그림 2에 표시된 단계를 안정적으로 완료할 수 있습니다.
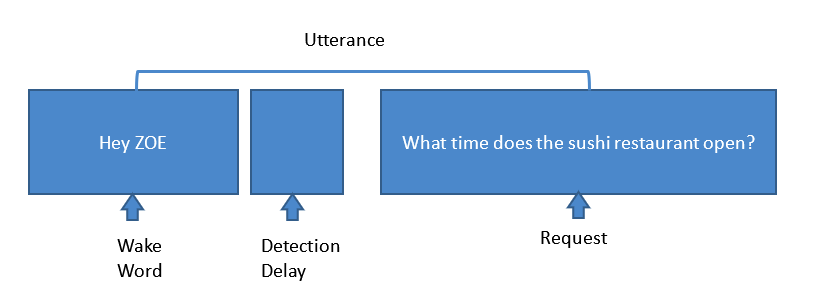
그림 2:일반적인 음성 도우미 요청과 관련된 단계. (출처:Harman Embedded Audio)
여기에서 조수석의 음성 비서 장치는 'Hey Zoe' 깨우는 단어를 감지합니다. 그런 다음 KWS가 키워드를 감지하면 잡음 억제 알고리즘을 기반으로 전체 마이크가 에너지를 소스로 전환하고 AC 잡음, TV, 비상관 잡음, 프로펠러 및 엔진 잡음, 바람 잡음, AEC와 같은 주변 잡음을 제거합니다. 등. Sonique 알고리즘은 이러한 모든 노이즈를 제거하고 시스템에 가능한 가장 깨끗한 신호를 가져오도록 조정됩니다. 그런 다음 시스템이 요청을 받으면 ASR 엔진이 이 음성을 텍스트로 변환합니다. 그런 다음 NLU 엔진은 이 텍스트를 원시 데이터로 변환하여 답을 얻습니다. 하지만 아직 끝나지 않았습니다. 원하는 답변을 얻기 위해 지식 스킬이 요청에 대한 답변을 제공하고 ASR 엔진이 해당 데이터 텍스트를 음성으로 변환하여 스피커를 통해 출력합니다.
또 다른 문제는 FRR(False Rate Rejection)을 둘러싼 것입니다. 스마트 스피커 성능을 측정하는 체크포인트 중 하나인 Wake Word FRR을 달성하는 과정은 시간과 비용이 많이 듭니다. 시스템은 깨우기 단어가 감지될 때마다 제품이 제대로 깨울 수 있는지 확인하는 데 사용됩니다. FRR을 달성하려면 훈련된 키워드가 필수적입니다. 우리의 경험에 따르면 훈련된 모델을 최상위 알고리즘과 결합하면 개발 팀이 문제를 극복하고 가능한 최고의 FRR을 달성할 수 있습니다. 웨이크 워드 응답은 시스템이 업계 표준을 통과하는지 확인하기 위해 실험실의 다양한 조건에서 추가로 테스트됩니다.
고유한 음성 에이전트를 사용할 때의 이점
음성 에이전트는 사용자 경험에 큰 가치를 제공합니다. 음악은 가장 크고 간단한 사용 사례이지만 음성 에이전트의 가치는 Spotify 계정을 원격으로 여는 것 이상으로 확장됩니다. 음성으로 전원을 켜고, 가전 제품과 상호 작용하고, 물을 끓이고, 수도꼭지를 켜는 등의 작업을 할 수 있습니다! 음성은 강력하고 상담원은 사용자에 대해 많이 알고 있습니다. 이것이 기업이 자체 데이터를 확보하려는 이유입니다. 즉, 소유하고, 저장하고, 보호해야 합니다.
음성 솔루션에는 광범위한 응용 프로그램이 있지만 핵심은 Apple, Windows 또는 Android에서 스마트 스피커, 랩톱 및 스마트폰과 관련된 여러 플랫폼에서 작동하는 기술을 활용하고 수집된 데이터를 활용하여 다음을 이해하는 에이전트를 구축하는 것입니다. 끊임없이 사용자의 요구를 배우고 기억합니다. 고유한 음성 에이전트를 생성하면 이러한 사용 유연성이 가능하며 동시에 데이터를 내부에 보관할 수 있습니다.
임베디드
Motoman SK-16M 로봇은 용접, 제거 및 취급 작업을 수행하는 Motoman 로봇의 SK 라인에 있는 많은 로봇 중 하나입니다. 많은 로봇과 마찬가지로 SK-16M은 AC 서보 모터, 타이밍 벨트, 감속기, 손목 장치 및 내부 배선을 포함하여 생산을 개선하기 위해 함께 작동하는 복잡한 부품 세트로 구성됩니다. 로봇의 많은 부분은 로봇이 움직이고 작업을 수행하는 데 도움이 됩니다. AC 서보 모터(부품 번호 HW9381136-A, HW9381137-A 및 HW9380837-A)는 로봇의 S, L, U 및 R 축에 있습니다.
산업용 로봇은 1980년대부터 본격적으로 사용되었습니다. 그 시기에 제조업체는 용접, 재료 취급 및 재료 제거와 같은 프로세스를 자동화함으로써 애플리케이션 속도를 높이면서 비용을 절감할 수 있다는 것을 깨달았습니다. 그러한 모델 중 하나는 Fanuc M6iB/6S였습니다. 이 로봇은 자재 취급 응용 분야에서 효율적이지만 생산을 계속 진행하기 위해 해마다 돌아가는 내부 부품입니다. M-6iB-6S 로봇의 모든 축에 있는 서보 모터(부품 번호 A06B-0202-B605 및 A06B-0223-B605)에는 로봇의 모든 부품에서 피드백을