

VHDL

산업 제조
순환 버퍼는 순차 프로그래밍 언어로 대기열을 생성하는 데 널리 사용되는 구성이지만 하드웨어에서도 구현할 수 있습니다. 이 기사에서는 블록 RAM에서 FIFO를 구현하기 위해 VHDL에서 링 버퍼를 생성할 것입니다.
FIFO를 구현할 때 많은 설계 결정을 내려야 합니다. 어떤 종류의 인터페이스가 필요합니까? 자원에 제약이 있습니까? 덮어쓰기 및 덮어쓰기에 탄력적이어야 합니까? 대기 시간이 허용됩니까? FIFO를 생성하라는 요청을 받았을 때 떠오르는 질문 중 일부입니다.
온라인에는 많은 무료 FIFO 구현과 Xilinx LogiCORE와 같은 FIFO 생성기가 있습니다. 그러나 여전히 많은 엔지니어는 자체 FIFO를 구현하는 것을 선호합니다. 모두 동일한 기본 대기열 및 대기열에서 제거 작업을 수행하지만 세부 사항을 고려할 때 크게 다를 수 있기 때문입니다.
링 버퍼는 최소 데이터 셔플링으로 버퍼링된 데이터를 저장하기 위해 연속 메모리를 사용하는 FIFO 구현입니다. 새 요소는 쓰기 시점부터 읽고 FIFO에서 제거될 때까지 동일한 메모리 위치에 유지됩니다.
두 개의 카운터는 FIFO의 위치와 요소 수를 추적하는 데 사용됩니다. 이 카운터는 데이터가 저장된 메모리 공간의 시작부터 오프셋을 나타냅니다. VHDL에서 이것은 배열 셀에 대한 인덱스가 됩니다. 이 기사의 나머지 부분에서는 이러한 카운터를 포인터라고 부를 것입니다. .
이 두 포인터는 머리입니다. 및 꼬리 포인터. 헤드는 항상 다음에 기록된 데이터를 포함할 메모리 슬롯을 가리키고 꼬리는 FIFO에서 읽을 다음 요소를 나타냅니다. 다른 변형이 있지만 이것이 우리가 사용할 변형입니다.
![]()
헤드와 테일이 동일한 요소를 가리키면 FIFO가 비어 있음을 의미합니다. 위의 이미지는 8개의 슬롯이 있는 FIFO의 예를 보여줍니다. 헤드와 테일 포인터는 모두 요소 0을 가리키며 FIFO가 비어 있음을 나타냅니다. 링 버퍼의 초기 상태입니다.
두 포인터가 다른 인덱스(예:3)에 있는 경우 FIFO는 여전히 비어 있습니다. 각 쓰기에 대해 헤드 포인터는 한 위치 앞으로 이동합니다. 꼬리 포인터는 FIFO의 사용자가 요소를 읽을 때마다 증가합니다.
포인터 중 하나가 가장 높은 인덱스에 있을 때 다음 쓰기 또는 읽기는 포인터가 가장 낮은 인덱스로 다시 이동하도록 합니다. 이것이 링 버퍼의 장점입니다. 데이터는 이동하지 않고 포인터만 이동합니다.

위의 이미지는 5회 쓰기 후 동일한 링 버퍼를 보여줍니다. 테일 포인터는 여전히 슬롯 번호 0에 있지만 헤드 포인터는 슬롯 번호 5로 이동했습니다. 데이터가 포함된 슬롯은 그림에서 밝은 파란색으로 표시됩니다. 꼬리 포인터는 가장 오래된 요소에 있고 머리는 다음 빈 슬롯을 가리킵니다.
머리가 꼬리보다 높은 인덱스를 가질 때 머리에서 꼬리를 빼서 링 버퍼의 요소 수를 계산할 수 있습니다. 위의 이미지에서 5개의 요소가 생성됩니다.

꼬리에서 머리를 빼는 것은 머리가 꼬리를 이끄는 경우에만 작동합니다. 위의 이미지에서 머리는 인덱스 2에 있고 꼬리는 인덱스 5에 있습니다. 따라서 이 간단한 계산을 수행하면 2 – 5 =-3이 되는데 의미가 없습니다.
해결책은 FIFO의 총 슬롯 수(이 경우 8)로 헤드를 오프셋하는 것입니다. 이제 계산 결과 (2 + 8) – 5 =5가 나오며 이것이 정답입니다.
꼬리는 머리를 영원히 쫓을 것이고 이것이 링 버퍼가 작동하는 방식입니다. 시간의 절반은 꼬리가 머리보다 높은 지수를 가질 것입니다. 데이터는 위 이미지에서 하늘색으로 표시된 것처럼 둘 사이에 저장됩니다.

전체 링 버퍼는 헤드 바로 뒤의 인덱스를 가리키는 꼬리를 갖습니다. 이 방식의 결과는 데이터를 저장하기 위해 모든 슬롯을 사용할 수 없으며 최소한 하나의 여유 슬롯이 있어야 한다는 것입니다. 위의 이미지는 링 버퍼가 가득 찬 상황을 보여줍니다. 열려 있지만 사용할 수 없는 슬롯은 노란색으로 표시됩니다.
링 버퍼가 가득 찼음을 나타내기 위해 전용 empty/full 신호를 사용할 수도 있습니다. 이렇게 하면 모든 메모리 슬롯이 데이터를 저장할 수 있지만 레지스터 및 LUT(룩업 테이블) 형태의 추가 논리가 필요합니다. 따라서 열린 상태로 유지 링 버퍼 FIFO 구현을 위한 체계입니다. 이는 더 저렴한 블록 RAM만 낭비하기 때문입니다.
FIFO에 대한 인터페이스 신호를 정의하는 방법은 링 버퍼의 가능한 구현 수를 제한합니다. 이 예에서는 고전적인 읽기/쓰기 활성화 및 비어 있음/전체/유효한 인터페이스의 변형을 사용할 것입니다.
쓰기 데이터가 있을 것입니다. FIFO로 푸시될 데이터를 전달하는 입력 측의 버스. 쓰기 가능도 있습니다. 이 신호는 주장될 때 FIFO가 입력 데이터를 샘플링하도록 합니다.
출력 측에는 읽기 데이터가 있습니다. 및 유효한 읽기 FIFO에 의해 제어되는 신호. 또한 읽기 활성화가 있습니다. FIFO의 다운스트림 사용자가 제어하는 신호.
비어 있음 그리고 전체 제어 신호는 고전적인 FIFO 인터페이스의 일부이므로 우리도 사용할 것입니다. 그것들은 FIFO에 의해 제어되며 그들의 목적은 FIFO의 상태를 리더와 작가에게 전달하는 것입니다.
조치를 취하기 전에 FIFO가 비어 있거나 가득 찰 때까지 기다리는 문제는 인터페이싱 로직이 반응할 시간이 없다는 것입니다. 순차 로직은 클록 사이클에서 클록 사이클 기준으로 작동하며, 클록의 상승 에지는 디자인의 이벤트를 타임 스텝으로 효과적으로 분리합니다.

한 가지 해결책은
구현에서 앞의 신호 이름은 empty_next입니다. 및 full_next , 단순히 접두사 이름보다 접미사 이름을 선호하기 때문입니다.

아래 이미지는 링 버퍼 FIFO의 엔티티를 보여줍니다. 포트의 입력 및 출력 신호 외에도 두 개의 일반 상수가 있습니다. RAM_WIDTH 일반은 입력 및 출력 단어의 비트 수, 각 메모리 슬롯에 포함될 비트 수를 정의합니다.
RAM_DEPTH 일반은 링 버퍼용으로 예약될 슬롯 수를 정의합니다. 하나의 슬롯은 링 버퍼가 가득 찼음을 나타내기 위해 예약되어 있으므로 FIFO의 용량은 RAM_DEPTH이 됩니다. – 1. RAM_DEPTH 상수는 타겟 FPGA의 RAM 깊이와 일치해야 합니다. 블록 RAM 프리미티브 내에서 사용되지 않은 RAM은 낭비되며 FPGA의 다른 로직과 공유할 수 없습니다.
entity ring_buffer is
generic (
RAM_WIDTH : natural;
RAM_DEPTH : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- Write port
wr_en : in std_logic;
wr_data : in std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Read port
rd_en : in std_logic;
rd_valid : out std_logic;
rd_data : out std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Flags
empty : out std_logic;
empty_next : out std_logic;
full : out std_logic;
full_next : out std_logic;
-- The number of elements in the FIFO
fill_count : out integer range RAM_DEPTH - 1 downto 0
);
end ring_buffer;
클록 및 재설정 외에도 포트 선언에는 클래식 데이터/읽기 및 쓰기 포트 활성화가 포함됩니다. 이는 업스트림 및 다운스트림 모듈에서 새 데이터를 FIFO로 푸시하고 가장 오래된 요소를 팝하는 데 사용됩니다.
rd_valid 신호는 rd_data 포트에 유효한 데이터가 있습니다. 이 이벤트는 rd_en의 펄스 후 1클럭 사이클만큼 지연됩니다. 신호. 이 기사의 끝에서 왜 이런 식으로 해야 하는지에 대해 더 자세히 이야기할 것입니다.
그런 다음 FIFO에 의해 설정된 빈/전체 플래그가 옵니다. empty_next empty 동안 요소가 1개 또는 0개 남아 있을 때 신호가 표시됩니다. FIFO에 0개의 요소가 있을 때만 활성화됩니다. 마찬가지로 full_next 신호는 1개 또는 0개 이상의 요소를 위한 공간이 있음을 나타내는 반면 full FIFO가 다른 데이터 요소를 수용할 수 없는 경우에만 주장합니다.
마지막으로 fill_count가 있습니다. 산출. 이것은 FIFO에 현재 저장된 요소의 수를 반영하는 정수입니다. 모듈에서 내부적으로 사용할 것이기 때문에 이 출력 신호를 포함시켰습니다. 엔티티를 통해 분리하는 것은 기본적으로 무료이며 사용자는 이 모듈을 인스턴스화할 때 이 신호를 연결되지 않은 상태로 둘 수 있습니다.
VHDL 파일의 선언적 영역에서 링 버퍼 모듈에서 내부 사용을 위한 사용자 정의 유형, 하위 유형, 신호 수 및 절차를 선언합니다.
type ram_type is array (0 to RAM_DEPTH - 1) of
std_logic_vector(wr_data'range);
signal ram : ram_type;
subtype index_type is integer range ram_type'range;
signal head : index_type;
signal tail : index_type;
signal empty_i : std_logic;
signal full_i : std_logic;
signal fill_count_i : integer range RAM_DEPTH - 1 downto 0;
-- Increment and wrap
procedure incr(signal index : inout index_type) is
begin
if index = index_type'high then
index <= index_type'low;
else
index <= index + 1;
end if;
end procedure;
먼저 RAM을 모델링할 새 유형을 선언합니다. ram_type 유형은 일반 입력에 따라 크기가 조정되는 벡터 배열입니다. 새 유형은 다음 줄에서 ram를 선언하는 데 사용됩니다. 링 버퍼에 데이터를 보관할 신호입니다.
다음 코드 블록에서 index_type을 선언합니다. , 정수의 하위 유형입니다. 범위는 RAM_DEPTH에 의해 간접적으로 관리됩니다. 일반적인. 하위 유형 선언 아래에서 인덱스 유형을 사용하여 두 개의 새로운 신호인 헤드 및 테일 포인터를 선언합니다.
그런 다음 엔터티 신호의 내부 복사본인 신호 선언 블록을 따릅니다. 엔티티 신호와 동일한 기본 이름을 갖지만 _i로 접미사가 붙습니다. 내부용임을 나타냅니다. inout을 사용하는 것은 좋지 않은 스타일로 간주되기 때문에 이 접근 방식을 사용하고 있습니다. 동일한 효과를 가지지만 엔터티 신호에 대한 모드입니다.
마지막으로 incr이라는 프로시저를 선언합니다. index_type을 사용합니다. 신호를 매개변수로 합니다. 이 하위 프로그램은 헤드 및 테일 포인터를 증가시키는 데 사용되며, 가장 높은 값에 있을 때 이를 다시 0으로 감쌉니다. 머리와 꼬리는 일반적으로 래핑 동작을 지원하지 않는 정수의 하위 유형입니다. 우리는 이 문제를 피하기 위해 절차를 사용할 것입니다.
아키텍처의 맨 위에서 우리는 동시 선언문을 선언합니다. 나는 쉽게 간과되기 때문에 일반 프로세스 전에 이러한 단일 라이너 신호 할당을 수집하는 것을 선호합니다. 동시 명령문은 실제로 프로세스의 한 형태입니다. 동시 명령문에 대한 자세한 내용은 다음을 참조하세요.
VHDL에서 동시 문을 만드는 방법
-- Copy internal signals to output empty <= empty_i; full <= full_i; fill_count <= fill_count_i; -- Set the flags empty_i <= '1' when fill_count_i = 0 else '0'; empty_next <= '1' when fill_count_i <= 1 else '0'; full_i <= '1' when fill_count_i >= RAM_DEPTH - 1 else '0'; full_next <= '1' when fill_count_i >= RAM_DEPTH - 2 else '0';
동시 할당의 첫 번째 블록에서 엔티티 신호의 내부 버전을 출력에 복사합니다. 이 라인은 엔터티 신호가 정확히 동시에 내부 버전을 따르도록 하지만 시뮬레이션에서 하나의 델타 주기 지연이 발생하도록 합니다.
동시 명령문의 두 번째이자 마지막 블록은 출력 플래그를 할당하는 곳으로 링 버퍼의 전체/비어 있음 상태를 나타냅니다. RAM_DEPTH를 기반으로 계산합니다. 일반 및 fill_count 신호. RAM 깊이는 변하지 않는 상수입니다. 따라서 플래그는 업데이트된 채우기 수의 결과로만 변경됩니다.
헤드 포인터의 기본 기능은 이 모듈 외부에서 쓰기 가능 신호가 발생할 때마다 증가하는 것입니다. head을 전달하여 이 작업을 수행합니다. 앞서 언급한 incr에 신호를 보냅니다. 절차.
PROC_HEAD : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
head <= 0;
else
if wr_en = '1' and full_i = '0' then
incr(head);
end if;
end if;
end if;
end process;
코드에는 추가 and full_i = '0'이 포함되어 있습니다. 덮어쓰기를 방지하기 위한 명령문입니다. 데이터 소스가 가득 찬 FIFO에 쓰기를 시도하지 않을 것이라고 확신하는 경우 이 논리를 생략할 수 있습니다. 이 보호 기능이 없으면 덮어쓰기로 인해 링 버퍼가 다시 비게 됩니다.
링 버퍼가 가득 찬 동안 헤드 포인터가 증가하면 헤드는 꼬리와 동일한 요소를 가리킬 것입니다. 따라서 모듈은 포함된 데이터를 "잊어버리고" FIFO 채우기가 비어 있는 것처럼 보입니다.
full_i 평가 헤드 포인터를 증가시키기 전에 신호를 보내면 덮어쓴 값만 잊어버립니다. 이 솔루션이 더 좋은 것 같습니다. 그러나 어느 쪽이든 덮어쓰기가 발생하면 이 모듈 외부의 오작동을 나타냅니다.
꼬리 포인터는 머리 포인터와 유사한 방식으로 증가하지만 read_en 입력이 트리거로 사용됩니다. 덮어쓰기와 마찬가지로 and empty_i = '0'를 포함하여 중복 읽기를 방지합니다. 부울 식에서.
PROC_TAIL : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
tail <= 0;
rd_valid <= '0';
else
rd_valid <= '0';
if rd_en = '1' and empty_i = '0' then
incr(tail);
rd_valid <= '1';
end if;
end if;
end if;
end process;
또한 rd_valid 모든 유효한 읽기에 대해 신호를 보냅니다. 읽은 데이터는 rd_en 이후의 클록 주기에서 항상 유효합니다. FIFO가 비어 있지 않은 경우 어설션되었습니다. 이 지식이 있으면 이 신호가 실제로 필요하지 않지만 편의를 위해 포함할 것입니다. rd_valid 모듈이 인스턴스화될 때 연결되지 않은 상태로 두면 신호가 합성에서 최적화됩니다.
합성 도구가 블록 RAM을 추론하게 하려면 리셋 없이 동기식 프로세스에서 읽기 및 쓰기 포트를 선언해야 합니다. 우리는 모든 클록 사이클에서 RAM을 읽고 쓸 것이며 제어 신호가 이 데이터의 사용을 처리하도록 할 것입니다.
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= wr_data;
rd_data <= ram(tail);
end if;
end process;
이 프로세스는 다음 쓰기가 언제 발생할지 모르지만 알 필요는 없습니다. 대신 계속해서 쓰고 있습니다. head 신호가 쓰기의 결과로 증가하면 다음 슬롯에 쓰기를 시작합니다. 이렇게 하면 작성된 값이 효과적으로 잠깁니다.
fill_count 신호는 가득 차고 비어 있는 신호를 생성하는 데 사용되며, 이는 차례로 FIFO의 덮어쓰기 및 읽기를 방지하는 데 사용됩니다. 채우기 카운터는 헤드 및 테일 포인터에 민감한 조합 프로세스에 의해 업데이트되지만 이러한 신호는 클럭의 상승 에지에서만 업데이트됩니다. 따라서 채우기 횟수도 클록 에지 직후에 변경됩니다.
PROC_COUNT : process(head, tail)
begin
if head < tail then
fill_count_i <= head - tail + RAM_DEPTH;
else
fill_count_i <= head - tail;
end if;
end process;
채우기 수는 머리에서 꼬리를 빼서 간단히 계산됩니다. 꼬리 인덱스가 머리보다 크면 RAM_DEPTH 값을 추가해야 합니다. 현재 링 버퍼에 있는 올바른 수의 요소를 가져오는 상수입니다.
library ieee;
use ieee.std_logic_1164.all;
entity ring_buffer is
generic (
RAM_WIDTH : natural;
RAM_DEPTH : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- Write port
wr_en : in std_logic;
wr_data : in std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Read port
rd_en : in std_logic;
rd_valid : out std_logic;
rd_data : out std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Flags
empty : out std_logic;
empty_next : out std_logic;
full : out std_logic;
full_next : out std_logic;
-- The number of elements in the FIFO
fill_count : out integer range RAM_DEPTH - 1 downto 0
);
end ring_buffer;
architecture rtl of ring_buffer is
type ram_type is array (0 to RAM_DEPTH - 1) of
std_logic_vector(wr_data'range);
signal ram : ram_type;
subtype index_type is integer range ram_type'range;
signal head : index_type;
signal tail : index_type;
signal empty_i : std_logic;
signal full_i : std_logic;
signal fill_count_i : integer range RAM_DEPTH - 1 downto 0;
-- Increment and wrap
procedure incr(signal index : inout index_type) is
begin
if index = index_type'high then
index <= index_type'low;
else
index <= index + 1;
end if;
end procedure;
begin
-- Copy internal signals to output
empty <= empty_i;
full <= full_i;
fill_count <= fill_count_i;
-- Set the flags
empty_i <= '1' when fill_count_i = 0 else '0';
empty_next <= '1' when fill_count_i <= 1 else '0';
full_i <= '1' when fill_count_i >= RAM_DEPTH - 1 else '0';
full_next <= '1' when fill_count_i >= RAM_DEPTH - 2 else '0';
-- Update the head pointer in write
PROC_HEAD : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
head <= 0;
else
if wr_en = '1' and full_i = '0' then
incr(head);
end if;
end if;
end if;
end process;
-- Update the tail pointer on read and pulse valid
PROC_TAIL : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
tail <= 0;
rd_valid <= '0';
else
rd_valid <= '0';
if rd_en = '1' and empty_i = '0' then
incr(tail);
rd_valid <= '1';
end if;
end if;
end if;
end process;
-- Write to and read from the RAM
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= wr_data;
rd_data <= ram(tail);
end if;
end process;
-- Update the fill count
PROC_COUNT : process(head, tail)
begin
if head < tail then
fill_count_i <= head - tail + RAM_DEPTH;
else
fill_count_i <= head - tail;
end if;
end process;
end architecture;
위의 코드는 링 버퍼 FIFO에 대한 전체 코드를 보여줍니다. 아래 양식을 작성하여 ModelSim 프로젝트 파일과 테스트벤치를 즉시 우편으로 받을 수 있습니다.
FIFO는 작동 방식을 보여주기 위해 간단한 테스트벤치에서 인스턴스화됩니다. 아래 양식을 사용하여 ModelSim 프로젝트와 함께 테스트벤치의 소스 코드를 다운로드할 수 있습니다.
일반 입력은 다음 값으로 설정되었습니다.
테스트벤치는 먼저 FIFO를 재설정합니다. 리셋이 해제되면 테스트벤치는 FIFO가 가득 찰 때까지 순차적 값(1-255)을 FIFO에 씁니다. 마지막으로 FIFO는 테스트가 완료되기 전에 비워집니다.
아래 이미지에서 테스트벤치의 전체 실행에 대한 파형을 볼 수 있습니다. fill_count 신호는 FIFO의 채우기 레벨을 더 잘 설명하기 위해 파형에 아날로그 값으로 표시됩니다.
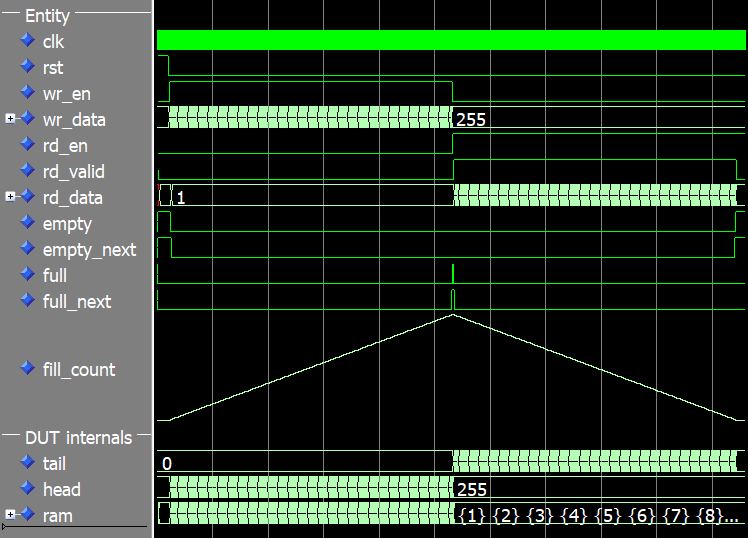
머리, 꼬리 및 채우기 수는 시뮬레이션 시작 시 0입니다. full 신호가 어설션되고 헤드의 값은 255이며 fill_count도 마찬가지입니다. 신호. RAM 깊이가 256인데도 채우기 수는 최대 255입니다. 이는 하나를 열어 두는 기능을 사용하기 때문입니다. 이 문서의 앞부분에서 논의한 것처럼 가득 찬 것과 비어 있는 것을 구별하는 방법입니다.
FIFO에 쓰기를 멈추고 읽기를 시작하는 전환점에서 헤드 값은 고정되고 테일 및 필 카운트는 감소하기 시작합니다. 마지막으로 시뮬레이션이 끝날 때 FIFO가 비어 있을 때 헤드와 테일 모두 값이 255이고 채우기 횟수는 0입니다.
이 테스트벤치는 데모 목적 이외의 다른 용도로는 적합하지 않은 것으로 간주되어야 합니다. FIFO의 출력이 전혀 올바른지 확인하는 자체 검사 동작이나 논리가 없습니다.
다음 주 기사에서 제약적 무작위 검증 주제에 대해 알아볼 때 이 모듈을 사용할 것입니다. . 이것은 더 일반적으로 사용되는 지시 테스트와 다른 테스트 전략입니다. 간단히 말해서 테스트벤치는 DUT(테스트 대상 장치)와 무작위로 상호 작용하며 DUT의 동작은 별도의 테스트벤치 프로세스를 통해 검증되어야 합니다. 마지막으로 미리 정의된 여러 이벤트가 발생하면 테스트가 완료됩니다.
다음 블로그 게시물을 읽으려면 여기를 클릭하십시오.
제한된 무작위 확인
Xilinx Vivado는 가장 널리 사용되는 FPGA 구현 도구이기 때문에 링 버퍼를 합성했습니다. 그러나 듀얼 포트 블록 RAM이 있는 모든 FPGA 아키텍처에서 작동해야 합니다.
링 버퍼를 독립형 모듈로 구현할 수 있도록 일반 입력에 일부 값을 할당해야 합니다. 이것은 설정을 사용하여 Vivado에서 수행됩니다. → 일반 → 제네릭/매개변수 메뉴는 아래 이미지와 같습니다.
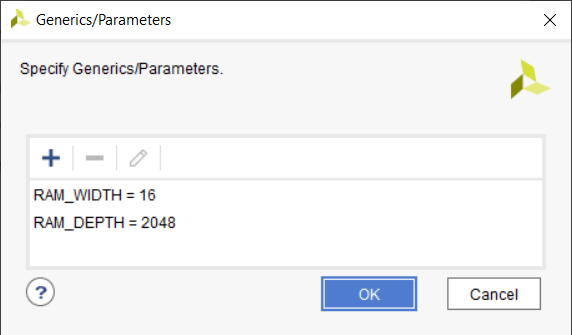
RAM_WIDTH 값 시뮬레이션에서와 동일한 16으로 설정됩니다. 하지만 RAM_DEPTH 내가 선택한 Xilinx Zynq 아키텍처의 RAMB36E1 기본 요소의 최대 깊이이기 때문에 2048로 변경합니다. 더 낮은 값을 선택할 수도 있었지만 여전히 동일한 수의 블록 RAM을 사용했을 것입니다. 더 높은 값을 사용하면 둘 이상의 블록 RAM이 사용됩니다.
아래 이미지는 Vivado에서 보고한 구현 후 리소스 사용량을 보여줍니다. 우리의 링 버퍼는 실제로 하나의 블록 RAM과 소수의 LUT 및 플립플롭을 사용했습니다.
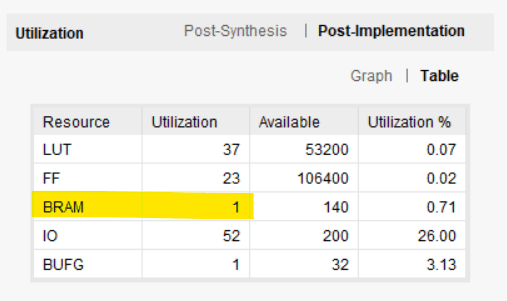
rd_en 및 rd_valid 신호가 실제로 필요합니다. 결국 데이터는 이미 rd_data에 있습니다. rd_en을 어설션할 때 신호. 이 값을 사용하고 링 버퍼가 FIFO에서 읽을 때 다음 클록 주기의 다음 요소로 건너뛰도록 할 수 없습니까?

엄밀히 말하면 valid가 필요하지 않습니다. 신호. 편의상 이 신호를 포함했습니다. 중요한 부분은 rd_en를 주장한 후 클럭 주기까지 기다려야 한다는 것입니다. 신호를 보내지 않으면 RAM이 반응할 시간이 없습니다.
FPGA의 블록 RAM은 완전히 동기식 구성 요소이며 데이터 읽기 및 쓰기 모두에 클록 에지가 필요합니다. 읽기 및 쓰기 클럭은 동일한 클럭 소스에서 올 필요는 없지만 클럭 에지가 있어야 합니다. 또한 RAM 출력과 다음 레지스터(플립플롭) 사이에는 논리가 있을 수 없습니다. RAM 출력을 클럭하는 데 사용되는 레지스터가 블록 RAM 프리미티브 내부에 있기 때문입니다.

위의 이미지는 wr_data에서 값이 전파되는 방식의 타이밍 다이어그램을 보여줍니다. RAM을 통해 링 버퍼에 입력하고 마지막으로 rd_data에 나타납니다. 산출. 각 신호는 상승 클록 에지에서 샘플링되기 때문에 읽기 포트에 표시되기 전에 쓰기 포트 구동을 시작한 후 3 클록 사이클이 걸립니다. 그리고 수신 모듈이 이 데이터를 활용할 수 있기 전에 추가 클록 사이클이 지나갑니다.
이 문제를 완화하는 방법이 있지만 FPGA에 사용되는 추가 리소스 비용이 발생합니다. 링 버퍼의 읽기 포트에서 하나의 클록 사이클 지연을 줄이는 실험을 해보자. 아래 코드 스니펫에서 rd_data를 변경했습니다. 동기 프로세스에서 ram에 민감한 조합 프로세스로의 출력 및 tail 신호.
PROC_READ : process(ram, tail)
begin
rd_data <= ram(tail);
end process;
불행히도 이 코드는 RAM 출력과 rd_data의 첫 번째 다운스트림 레지스터 사이에 조합 논리가 있을 수 있기 때문에 블록 RAM에 매핑할 수 없습니다. 신호.
아래 이미지는 Vivado에서 보고한 리소스 사용량을 보여줍니다. 블록 RAM이 LUTRAM으로 대체되었습니다. LUT에 구현된 분산형 RAM의 한 형태. LUT 사용량은 37 LUT에서 947로 급증했습니다. 조회 테이블과 플립플롭은 블록 RAM보다 더 비싸기 때문에 블록 RAM이 처음부터 있는 이유입니다.
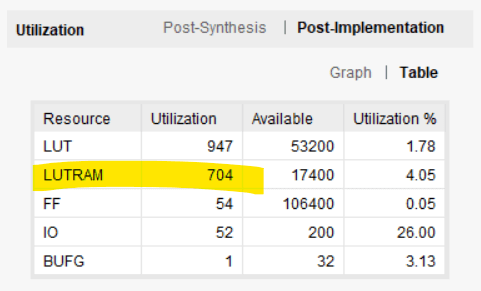
블록 RAM에서 링 버퍼 FIFO를 구현하는 방법에는 여러 가지가 있습니다. 다른 디자인을 사용하여 추가 클록 주기를 절약할 수 있지만 추가 지원 논리의 형태로 비용이 듭니다. 대부분의 애플리케이션의 경우 이 문서에 제공된 링 버퍼로 충분합니다.
업데이트:
AXI 준비/유효한 핸드셰이크를 사용하여 블록 RAM에 링 버퍼 FIFO를 만드는 방법
다음 블로그 게시물에서는 제약적 무작위 검증을 사용하여 링 버퍼 모듈을 위한 더 나은 테스트벤치를 만들 것입니다. .
다음 블로그 게시물을 읽으려면 여기를 클릭하십시오.
제한된 무작위 확인
VHDL
이전 자습서에서 For-Loop를 사용하여 정수 범위를 반복하는 방법을 배웠습니다. 그러나 고정된 정수 범위보다 루프를 더 자세히 제어하려면 어떻게 해야 할까요? 이를 위해 While 루프를 사용할 수 있습니다. While 루프는 테스트하는 표현식이 true로 평가되는 한 계속해서 동봉된 코드를 반복합니다. . 따라서 While-Loop는 얼마나 많은 반복이 필요한지 미리 알 수 없는 상황에 적합합니다. 이 블로그 게시물은 기본 VHDL 자습서 시리즈의 일부입니다. While 루프의 구문은 다음과 같습니다. while <
새로운 프로그래밍 언어를 배울 때 저는 항상 인쇄하는 방법을 배우는 것으로 시작하는 것을 좋아합니다. Hello World! 출력을 마스터하면 환경이 작동하고 있음을 알 수 있습니다. 또한 언어의 기본 골격, 출력을 생성하는 데 필요한 최소한의 코드도 보여줍니다. 라고 생각할 수도 있지만 VHDL은 하드웨어 설명 언어인데 어떻게 텍스트를 출력할 수 있습니까? FPGA에 연결된 화면이 필요하고 그 사이에 모든 종류의 로직이 필요하며 이는 전혀 간단하지 않습니다. 이 모든 것이 사실이지만 FPGA와 ASIC은 잠시 잊고 VHDL 언어